从前,有两个表匠,一个叫霍拉,一个叫坦普斯。两人都很受顾客的欢迎,他们各自的工场中的电话总是响个不停,因为老有新主顾上门。不过,霍拉发了大财,坦普斯却越来越穷,最后连店铺都给亏没了。这是为什么呢?他们做的表都是由1000个零件组成。坦普斯做表的方式是连续地把一只表从头做到尾,如果尚未装完一只表就不得不中途放下(比如说要去接客户电话了),那么装了一半的表就会立刻散掉,又得从头装起。顾客们越喜欢他的表,他的电话就越多,也就越难得到足够的不被打断的时间来装成一只表。霍拉做的表并不比坦普斯的简单。但他经过设计,用十个零件装成一个组件。十个组件又可装成更大的组件。十个大组件构成的系统就是整只表。因此,当霍拉不得不放下装了一部分的表去接电话时,他只损失了一小部分活儿,他装表所用工时只是坦普斯所用工时的一个零头。…在这个寓言里面,我的中心思想是,具有复杂性的系统最好是采取层级结构的形式,而层级结构有一些与系统的具体内容无关的共同性质。我将论证说,层级结构是构造复杂事物的建筑师们所使用的主要结构方式之一。
----H.Simon[1]《The Sciences of the Artificial》
一个计算任务可以很简单,使用几个语句进行描述,执行之后就可以得到结果,但是如果说我们人类使用计算机只是进行那种简单的计算,显然是浪费。而复杂的计算任务,则和任何复杂事物一样,具有非常庞大的内部结构,人类解决复杂问题的一般思路,就是把一个大的结构分解为相对比较小的结构,如果可能就一直分解到非常简单的结构,分别解决了那些简单结构的问题,按照我们分解大问题的逻辑,也就解决了开始的复杂问题。
如何运用程序语言来表达这个解构的思路,就是本篇我们要讨论的主要论题。
首先我们讨论一个FORTRAN程序所可以具有的结构,按照这个语言对程序结构模本的规定,我们就可以规划相应的针对计算任务的问题解构方式。
所谓FORTRAN程序的结构,就是一个FORTRAN程序可以包含那些程序单位,然后这些单位又必须如何组装在一起。
所以我们分类讨论了FORTRAN的程序单位之后,就需要讨论数据流与指令流是如何进行不同程序单位之间的通讯的,通过这种通讯,一个由许多程序单位组成的FORTRAN程序就构成了一个有机的整体,恢复了被支解的问题的本来结构。
特别的,我们还需要讨论最为重要的程序单位,就是过程,它的可执行程序单位的主体。其中FORTRAN语言以标准形式给出的固有过程,相当于为解决常见计算问题而准备的常用工具,熟练使用它们可以达到事半功倍的效果。
[1] Herbert A. Simon,1916-2001,20世纪所谓“认知科学革命”的核心人物,人工智能的巨擘,在计算机科学和心理学领域都作出了开创性贡献。1975年获得图灵奖,1978年以决策理论荣膺诺贝尔经济学奖,1993年美国心理学协会授予他终生杰出成就奖,1994年获选中科院外籍院士,生前多次访华。
一个FORTRAN程序可以由那些单位组成,在第一篇以及第4章都已经简单涉及过,在这里我们要详尽地讨论这个问题,特别是给出每种程序单位的结构与功能。
FORTRAN的程序单位分为两大类:
● 可执行程序单位;
● 不可执行程序单位。
其中可执行程序单位,用来执行一个完整的功能,包括:
● 主程序;
● 外部函数子程序;
● 外部子例行程序子程序。
不可执行程序单位,用来为其他程序单位提供定义,包括:
● 模块程序单位;
● 数据块程序单位。
因此上面的五种类型的程序单位构成了FORTRAN程序的基本单位,不过在后面我们会看到,数据块程序单位属于早期版本的遗留物,完全是多余的。
一个完整的FORTRAN程序至少需要一个主程序,而且也只能有一个主程序。
一般说来,要完成一个完整的计算任务,除了一个主程序之外,往往还需要有函数以及子例行程序作为辅助,这时,主程序的作用就还包括驱动与管理这些作为过程的外部子程序,使得它们构成一个整体,从而完整地解决相关计算问题。
模块程序单位主要是提供给编程者用来组织程序元素的。一个模块程序单位包含了如下几个方面的内容:
● 数据声明;
● 派生类型定义;
● 过程界面信息;
● 供其他程序单位使用的子程序定义。
因此这样一个程序单位本身不是可执行程序单位。
数据块程序单位用于给出命名公用块里面的变量的初始值,因此同样不是可执行程序单位。由于FORTRAN的现代版本引入了模块结构,而模块能够提供全局的数据初始化,因此数据块程序单位几乎可以说是多余的。
由于在第13章我们将专门讨论过程以及过程的应用,因此属于过程的外部函数子程序和外部子例行程序子程序,在本章都只是简略说明,需要详细讨论的是主程序和模块。
各种程序单位里面并不是能够使用任何FORTRAN语句,语句类型与程序单位之间的兼容性在下面的表中予以说明。
表12-1 语句与程序单元的兼容性
|
语 句 |
主程序 |
模块说明部分 |
数据块 |
外部子程序 |
模块子程序 |
内部子程序 |
界面体 |
|
USE语句 |
可 |
可 |
可 |
可 |
可 |
可 |
可 |
|
ENTRY语句 |
否 |
否 |
否 |
可 |
可 |
否 |
否 |
|
FORMAT语句 |
可 |
否 |
否 |
可 |
可 |
可 |
否 |
|
几种声明语句* |
可 |
可 |
可 |
可 |
可 |
可 |
可 |
|
DATA语句 |
可 |
可 |
可 |
可 |
可 |
可 |
否 |
|
派生类型定义 |
可 |
可 |
可 |
可 |
可 |
可 |
可 |
|
界面块 |
可 |
可 |
否 |
可 |
可 |
可 |
可 |
|
语句函数# |
可 |
否 |
否 |
可 |
可 |
可 |
否 |
|
CONTAINS |
可 |
可 |
否 |
可 |
可 |
否 |
否 |
|
可执行语句 |
可 |
否 |
否 |
可 |
可 |
可 |
否 |
注意:
*几种声明语句包括:PARAMETER语句,IMPLICIT语句,类型声明语句以及说明语句。
#语句函数语句属于过时语言成分。
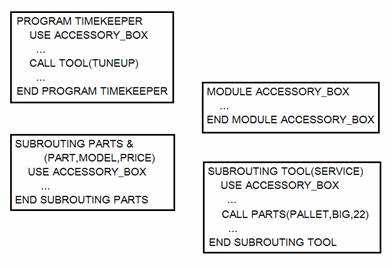
一个FORTRAN程序总是从主程序的第一个可执行语句开始运行,在第三章我们已经讨论过一个完整FORTRAN程序的结构。在下面的图12-1中,我们再给出一个完整FORTRAN程序的示意图,它包含了一个主程序,一个模块,以及两个子例行程序。
图12-1 钟表制作程序的结构
在上面的例子里面,我们假设在装配一块钟表时,零件装配与工具配套分别由两个徒弟完成,那么等负责工具配套的徒弟把零件都放置在适当的工具旁边的时候,就可以让钟表匠开始总的钟表装配工作了。
因此模块ACCESSORY_BOX(附件箱)里面包含了子例行程序PARTS(零件)与TOOL(工具)所需要的一切数据与过程信息。主程序调用了子例行程序TOOL,而主程序本身不需要模块ACCESSORY_BOX里面的信息。
主程序说明了整个FORTRAN程序的逻辑结构,同时整个程序的运行就是从主程序的第一个可执行语句开始的。不过从形式上看,一个主程序和外部子程序其实的非常类似的。
一个主程序包括如下三个基本部分:
● 说明部分。
这个部分定义了程序的数据环境。
● 运行部分。
整个程序从这个部分的第一个可执行语句开始,该部分给出了整个程序运行的逻辑结构。
● 内部子程序部分。
处于主程序内部的与主程序共享数据的过程。
下面我们分小节说明主程序的说明部分和运行部分,由于内部子程序部分由一个或多个内部过程组成,而内部过程的讨论见12.3,因此在12.2略过。
终止主程序运行的方式有如下两种:
● 在程序的任意位置执行STOP语句,就能即刻终止整个程序。所谓任意位置,包括组
成程序的任意程序单位的任意位置。
● 程序的运行到达主程序的最后一个语句。
主程序的形式(R1101)如下:
[PROGRAM program-name]
[specification-part]
[execution-part]
[internal-subprogram-part]
END [PROGRAM [program-name]]
下面是一个最最简单的FORTRAN程序:
【例12-1】
END
下面是一个稍微有意思一点的最简单程序:
【例12-2】
PROGRAM HI
PRINT*,“HELLO”
END
主程序的一般规则如下:
● PROGRAM语句作为主程序的程序头是可选的,但是其他的程序单位都必须具有程序头。
● 如果程序名称出现在END语句当中的话,那么该名称必须和PROGRAM语句里面的名称一样,并且放置在关键词的后面。不能单独出现END语句当中。
● 主程序不提供哑元。
● 主程序不能在任何位置被引用,也就是说,主程序不能被直接或间接地递归运行。
● 主程序不能包含RETURN语句和ENTRY语句,不过主程序里面的内部过程可以包含RETURN语句。
主程序的说明部分主要就是用来描述程序的数据环境。
主程序里面所能够包含的语句类型见表12-1,具体列出如下表12-2:
表12-2 主程序说明部分允许使用的语句
|
ALLOCATABLE |
PARAMETER |
|
COMMON |
POINTER |
|
DATA |
SAVE |
|
DIMENSION |
TARGET |
|
EQUIVALENCE |
USE |
|
EXTERNAL |
派生类型定义 |
|
FORMAT |
界面块 |
|
IMPLICIT |
语句函数语句 |
|
INTRINSIC |
类型声明语句 |
|
NAMELIST |
|
主程序的说明部分的一般规则如下:
● OPTIONAL以及INTENT属性或语句都不能在主程序的说明部分出现,因为它们都只能应用于哑元。
● 可访问性说明PUBLIC以及PRIVATE都不能出现于主程序,因为它们都只能应用于模块内部。
● 在主程序里面,动态对象没有意义。
● 尽管在主程序里面可以使用SAVE属性或语句,但它们在主程序里面并没有实际的作用。
主程序的运行部分由可执行语句构成,能够出现在主程序的运行部分的语句列出如下表12-3所示:
表12-3 主程序运行部分允许使用的语句
|
ALLOCATE |
GO TO |
|
BACKSPACE |
IF |
|
CALL |
IF结构 |
|
CASE结构 |
INQUIRE |
|
CLOSE |
NULLIFY |
|
CONTINUE |
OPEN |
|
CYCLE |
|
|
DATA |
READ |
|
DEALLOCATE |
REWIND |
|
DO结构 |
STOP |
|
END |
WHERE |
|
ENDFILE |
WHERE结构 |
|
ENTRY |
WRITE |
|
EXIT |
算术IF语句 |
|
FORALL |
赋值语句 |
|
FORALL结构 |
计算GO TO语句 |
|
FORMAT |
指针赋值语句 |
内部过程和外部过程的主要差别就在于它们的的位置不同:内部过程必须封装在主程序或其他过程子程序内部,这就导致以下后果:
● 内部过程的名称是局部的而不是全局的;
● 内部过程只能被包含了它的定义的程序单位所引用;
● 内部过程能够访问它的宿主的数据对象;
● 内部过程可以递归,不能包含ENTRY语句,也不能作为实元传递。
构造内部过程的主要原因如下:
● 内部过程提供了能够很方便地访问宿主环境的过程。
● 内部过程提供了一种具有语句函数功能的多语句形式。
● 便于模块设计以及具有更好的软件工程效能。
内部过程之所以能够提高安全性以及灵活性,是因为其界面非常清晰。
宿主的内部过程部分的形式(R210)为:
CONTAINS
internal-subprogram
[internal-subprogram]…
其中的内部子程序由一个或多个内部过程组成,而内部过程或者是由如下形式(R1216)的函数组成:
function-statement
[specification-part]
[execution-part]
END FUNCTION [function-name]
或者是由如下形式(R1221)的子例行程序组成:
subroutine-statement
[specification-part]
[execution-part]
END SUBROUTINE [subroutine-name]
【例12-3】
PROGRAM WEATHER
…
CONTAINS
FUNCTION STORM(CLOUD)
…
END FUNCTION STORM
END
其中的过程STORM就是主程序WEATHER里面的一个内部过程。
内部过程的一般规则如下:
● 内部过程内部不能再包含内部过程,即内部过程不能嵌套。
● 内部过程不能包含ENTRY语句。
● 内部过程不能包含PUBLIC和PRIVATE属性或语句
● 内部过程不能作为实元传递。
● 内部过程的说明部分除了可以包含主程序的说明部分所许可的语句之外,还可以包含INTENT语句以及OPTIONAL语句。
● 内部过程的运行部分除了可以包含主程序的运行部分所许可的语句之外,还可以包含RETURN语句。
● 在CONTAINS语句之后,至少需要有一个内部子程序。
内部过程可以被它的宿主的运行部分引用,也能够被同一个宿主里面的所有内部过程引用,包括它自身,因此内部过程可以直接或间接地使用递归的形式。
内部过程名称属于局部名称,因此满足如下规则:
● 内部过程名称具有比相同名称的外部过程或固有过程更高的优先级。
● 内部过程名称必须不同于任何同一个宿主里面的其他内部过程的名称,也必须不同于任何通过模块进入宿主或进入该内部过程的名称。
● 内部过程的名称必须不同于任何宿主或自身内部的其他局部名称,也必须不同于通过USE语句可访问的名称。
有关宿主以及内部过程里面的其他名称所需要遵循的规则参见第15章有关宿主关联的内容。
内部过程当中的某些变量有可能并非源自内部过程本身,而是从内部过程的宿主单位继承而来的,这样的变量被称为宿主关联的,它反映了内部程序与宿主在数据交流方面的密切关系。
宿主关联作为一种数据通讯方式,同样存在于模块过程与其作用域单位之间,因此我们将在第15章的更为一般的情形下讨论它。
同样外部子程序是由一个或多个外部过程组成,因此下文当中,我们将根据具体的上下文交替使用外部子程序与外部过程这两个概念。
外部过程与内部过程从语法上来看,实质上是一致的,因为毕竟它们都是属于过程,因此外部子程序的语法形式和内部子程序一样,即:
外部子程序由一个或多个外部过程组成,而外部过程或者是由如下形式(R1216)的函数组成:
function-statement
[specification-part]
[execution-part]
[internal-subprogram-part]
END FUNCTION [function-name]
或者是由如下形式(R1221)的子例行程序组成:
subroutine-statement
[specification-part]
[execution-part]
[internal-subprogram-part]
END SUBROUTINE [subroutine-name]
这是两种不同风格的过程形式。
同时,外部过程与内部过程又具有如下一些很重要的差别:
● 对于一个FORTRAN程序来说,外部子程序是全局性的,因为它可以在任何位置被调用或引用,相反,内部过程则只是对于它的宿主而言是已知的。
● 外部过程的界面在它被其他过程引用的时候,并非已知的,因为外部过程一般都是单独编译的;相反,对于内部过程来说,它是由它的宿主单位编译的,因此在它的宿主单位引用它的时候,它的界面信息必定已经给出了。
具有与生俱来的显式界面是内部过程或模块过程的一个很大的优点,它的好处将在第13章讨论。相比之下,外部过程就只能单独给出它的界面信息。
● 从FORTRAN标准语法上来看,外部过程可以包含内部过程,而内部过程则不能包含内部过程,不过也有许多FORTRAN的实现都允许内部过程的嵌套。
下面是外部过程的两个不同形式的例子:
【例12-4】
FUNCTION CIRCLE(NET)
INTEGER CIRCLE
CIRCLE=NODE
…
END FUNCTION
这个例子使用了函数作为外部过程。
【例12-5】
SUBROUTINE TAYLOR(I,J)
I=…
J=…
END SUBROUTINE
这个例子使用了子例行程序作为外部过程。
外部子程序的一般规则如下:
● 外部子程序作为程序单位的头,即FUNCTION语句或SUBROUTINE语句,是不能省略的,这点与主程序不同。
● 如果在END语句出现过程名称,那么它必须与头语句里面的过程名称一样。
● 用于哑元的INTENT和OPTIONAL属性或语句可以出现在外部子程序的说明部分,注意它们只能应用于哑元。
● 外部子程序的说明部分和运行部分都可以包含ENTRY语句;运行部分可以包含RETURN语句。
● 外部子程序不能包含用来说明可访问性的PUBLIC或PRIVATE属性或语句。
● 外部过程可以采用直接或间接的递归形式,这时,在该过程的头语句里面必须使用关键词RECURSIVE。
● 一个外部子程序对于在它内部定义的内部过程而言,就是宿主单位。
● 外部过程名称可以在过程引用的时候作为实元来使用,相应的哑元就是引用它的过程里面的过程哑元。
无论是外部过程,内部过程或模块过程,作为过程的更加一般的讨论参见第13章。
模块是到了FORTRAN90版标准之后才引入的一个极其强大的程序结构单位形式。只要是多于一个程序单位都需要使用的任何东西,都可以封装在一个模块里面,供相关的程序单位使用。
在FORTRAN的早期版本当中,为了解决一些程序要素的重复使用问题,使用了INCLUDE行,它的功能纯粹只是把一段源码原封不动地引入某个程序(参见第四章),相当于“COPY+PASTE”的功能,以避免在重复写入别处的源码段时可能出现的笔误,也节省编写源码的工作量。但是这样一种解决方式是非常有局限性的,因为这完全只是一种形式上的重用,根本不具有灵活性与多功能性,因此到了制订FORTRAN90标准的时候,就引入了符合现代编程风格的模块结构,使得INCLUDE行逐渐退出了历史舞台。
模块为FORTRAN解决了如下的问题:
● 解决了大量的与全局性数据公用块相关联的可靠性问题,因为对于全局性数据来说,名称关联比存储关联更为有必要。
● 提供了更为可靠的定义派生类型的方式。
● 许多的情形下都要求显式的界面,而模块正好满足了这种需求。
● 提供了极其重要的信息隐藏功能,模块保证了可靠性所要求的有效的封装与隐藏功能。
尽管模块可以包含被其他程序单位的运行部分引用的可执行过程,但它自身并不是可执行的程序单位,实质上它只是被动地提供信息,在这个意义上,模块就已经是足够强大的管理程序的组织与简化程序设计的工具。
模块的语法形式(R1104)为:
MODULE module-name
[specification-part]
[module-subprogram-part]
END [MODULE [module-name]]
模块的名称如果出现在END语句,那么必须和MODULE语句里面的模块名称一样。
模块的说明部分与其他的程序单位的说明部分非常类似,它可以包含的语句如下表12-4所示:
表12-4 模块说明部分允许使用的语句
|
ALLOCATABLE |
POINTER |
|
COMMON |
PRIVATE |
|
DATA |
PUBLIC |
|
DIMENSION |
SAVE |
|
EQUIVALENCE |
TARGET |
|
EXTERNAL |
USE |
|
IMPLICIT |
派生类型定义 |
|
INTRINSIC |
界面块 |
|
NAMELIST |
类型声明语句 |
|
PARAMETER |
|
模块的说明部分的一般规则如下:
● 不允许使用OPTIONAL和INTENT属性或语句。
● 不允许使用ENTRY语句。
● 不允许使用FORMAT语句
● 不允许使用动态对象。
● 不允许使用语句函数语句。
● 可以使用PUBLIC和PRIVATE属性或语句。
注意在模块的说明部分中使用SAVE属性或语句是非常必要的,因为SAVE能够保证模块里面的数据对象,不会受到使用该模块的其他程序单位的影响。如果没有使用SAVE属性或语句的话,那么相应的数据对象常常会被使用该模块的其他程序单位去定义,而使用SAVE属性或语句,则能够保证相应的数据对象保留其定义状态。
【例12-6】
MODULE DATA1
SAVE
INTEGER::X,IX
REAL::K=0.01
REAL::Y(10,20),Z(20,30)
END MODULE DATA1
SUBROUTINE TASK1
USE DATA1
…
END SUBROUTINE TASK1
在上面的模块DATA1当中,声明了三个标量变量:X,IX和K,其中K给出了初始值,还有两个数组:Y(10,20),Z(20,30),这5个数据对象都是全局性的,都可以在任何时候被其他的程序单元使用。在后面的子例行程序TASK1里面就通过USE语句使用了这5个变量。
在语法上,模块的子程序部分类似于主程序的内部过程部分或外部子程序。
模块的子程序部分由一个或多个模块过程组成,它们通过宿主关联共享模块的数据环境,不过模块的子程序部分与内部子程序有如下两个基本的差别:
● 模块过程的组织结构,规则与限制都与外部过程的一样,而与内部过程的不同,例如模块过程可以包含内部过程,而内部过程不能包含内部过程。
● 模块过程并非严格地局限于宿主模块,也不是全局性地面对整个程序,只有使用了模块的程序单位才能访问没有标记为PRIVATE的模块过程。
模块子程序部分的语法形式(R212)为:
CONTAINS
module-subprogram
[module-subprogram]…
其中的模块子程序或者是由如下形式(R1216)的函数组成:
function-statement
[specification-part]
[execution-part]
[internal-subprogram-part]
END FUNCTION [function-name]
或者是由如下形式(R1221)的子例行程序组成:
subroutine-statement
[specification-part]
[execution-part]
[internal-subprogram-part]
END SUBROUTINE [subroutine-name]
这是两种不同风格的过程形式。
模块过程的一个例子如下:
【例12-7】
MODULE INTERNAL
….
CONTAINS
FUNCTION SET_INTERNAL(KEY)
…
END FUNCTION
END
注意模块过程通过宿主关联来访问它的宿主模块的数据对象,但不能访问使用该模块的程序单位的数据对象。
CONTAINS语句后面至少需要有一个内部子程序。
任何一个程序单位都可以通过USE语句来使用一个模块里面的说明与定义。这样一种从模块外部的程序单位到模块内部的命名对象的访问,导致一种关联,称为使用关联。
USE语句必须跟在要使用模块的程序单位的头语句后面,对于USE语句的数目并没有具体的限制。
每个模块里面的命名对象都具有PUBLIC属性或者PRIVATE属性,这两个属性决定了该对象是否可以被使用该模块的程序单位所使用,即:
● 如果具有PUBLIC属性,则可以被使用该模块的程序单位所使用,当然这种可访问性也有可能遭到USE语句本身的限制。
● 如果具有PRIVATE属性,则不能被使用该模块的程序单位所使用。
下面的图12-2表示了模块内对象与外部程序单位的使用关联。

图12-2 模块内对象与外部程序单位的使用关联
USE语句最简单的功能就是通过使用该语句,外部程序单位可以访问模块内部的所有公用对象。
USE语句的语法形式(R1107)为:
USE module-name
如果外部程序单位在引用了模块的公用命名对象后,导致与程序单位自身的命名对象的冲突,或违反了该程序单位的命名约定,那么就需要在USE语句当中加上改名选项,即:
USE module-name,rename-list
其中改名列表(rename-list)里面的每个元素都具有以下形式(R1108):
local-name=>module-entity-name
即给每个模块内需要使用的对象的名称(module-entity-name)重新赋予一个新的程序单位内使用的本地名称(local-name)。
【例12-8】
USE FOURIER
USE S_LIB, PRESSURE => X_PRES
注意改名的形式与赋值语句的相似性,但是改名属于USE语句内的一个选项,而不是一个单独的语句。
如果要想让外部程序单位只是访问一个模块的部分公用对象,则使用如下形式的USE语句:
USE module-name,ONLY:access-list
即在USE语句的ONLY子句里面显式指出可以访问的公用对象。对于这些公用对象也可以根据程序单位的本地要求进行改名。
可访问对象列表里面的元素的形式可以具有如下这些形式(R1109):
[local-name=>]module-entity-name
OPERATOR(defined-operator)
ASSIGNMENT(=)
即除了模块对象名称之外,还可以是模块内定义的自定义运算或赋值界面。
【例12-9】
USE TENSOR1,ONLY:X,Y,OPERATOR(.CROSS.)
USE MONTHS,ONLY:JANUARY=>JAN,MAY
在模块内部,如下类型的对象都可以被声明,定义,或说明,并且可以具有公用属性,然后就可以被外部程序单位通过USE语句而使用,其中除了自定义运算和赋值界面之外,还可以被改名。这些对象包括:
● 经过声明的变量;
● 命名常量;
● 派生类型定义;
● 过程界面;
● 模块过程和固有过程;
● 通用识别符;
● 名称列表集合。
公用块也可以放置在模块里面,由于公用块的名称总是全局性的,因此公用块名称总是可以被模块外部访问,并且不需要使用额外的USE语句,不过如果要对公用块里面的变量进行改名,则可以使用加改名选项的USE语句。
在默认情况下,模块里面的上述所有对象都是具有PUBLIC属性的,如果使用一个PRIVATE语句加上空的对象列表,则把模块内的所有对象的属性改为私用的了。
当然可以使用PRIVATE语句或在类型声明语句当中附加PRIVATE属性的方式单独地对单个对象赋予私用属性。
而一旦默认可访问属性被改为PRIVATE之后,还可以使用PUBLIC语句或在类型声明语句当中附加PUBLIC属性的方式单独地对单个对象赋予公用属性。
相比之下,模块内部的任何对象,包括模块内部的模块过程里面的对象,都可以通过宿主关联而被模块过程访问。
模块内部对象的这两种被访问方式以及它们各自的特点,示意于下面的图12-3。

图12-3 模块内对象的使用关联与宿主关联
把USE-ONLY语句和模块内的PUBLIC以及PRIVATE属性这两种方式综合起来,就使得模块兼具了信息安全性和数据访问灵活性。
当一个外部程序单位使用某个模块时,有可能出现以下两种名称冲突的情形:
● 模块内的公用对象和外部程序单位内的本地对象具有相同的名称;
● 一个外部程序单位同时使用了两个或多个模块,它们的公用对象具有相同的名称。
这样的冲突只有在产生冲突的名称永远也不会被引用的情形下才能够容忍,否则,就必须使用改名选项或USE语句的ONLY子句,来限制相关对象的使用。
【例12-10】
MODULE BLUE
INTEGER A,B,C
END MODULE BLUE
MODULE GREEN
USE BLUE,ONLY:A1=>A
REAL B,C
END MODULE GREEN
!在下面的程序RED里面:
!用A1或A访问整型A;
!用B访问整型B;
!用B1访问实型B;
!C不能被访问,因为存在名称冲突。
PROGRAM RED
USE BLUE !访问了A,B,
USE GREEN B1=>B !用A1访问A,用B1访问B,访问C。
…
END PROGRAM
当一个外部程序单位通过使用USE语句而访问一个模块里面它自身所不具有的对象时,就意味着这些被访问的对象与外部程序发生了关联,这种关联称为使用关联;相比之下,在模块的内部,当模块里面的模块过程访问其宿主模块的对象时所发生的关联,称为宿主关联。
使用关联与宿主关联具有如下两个重要的差别:
● 一个模块的隐式类型规则对于使用它的外部程序单位的环境没有影响。
● 通过USE语句来访问的对象,不能在它所在的本地重说明,改名不属于重说明范畴。
不过这个规则存在一个例外,即假如外部程序单位本身是一个模块,那么它从某个模块访问得到的对象,可以在它的内部重新说明为具有PRIVATE属性,显然,该对象在原来的模块里,是具有PUBLIC属性的。
【例12-11】
设一个程序单位使用如下所示的模块M2,那么它就只能使用对象X,而不能使用对象Y,因为Y在M2里面被重说明为具有PRIVATE属性,尽管Y来自模块M1,并且在M1里面是具有PUBLIC属性的。
MODULE M2
USE M1,ONLY:X,Y
PRIVATE Y
…
END MODULE M2
对象不能被重说明意味着同一个公用块,也不能在模块和相应的外部程序单位里面被说明。这也就意味着本地的对象不能和从模块里面访问得到的对象等价。
一个模块可以一个或多个COMMON块,这些COMMON块总是可以被访问的,这意味着它们不能在使用它们的宿主模块的外部程序单位不能再次声明它们。
因为从一个模块里面访问得到的名称不能在本地被重新说明,所以要从不同的模块里面访问同一个名称,就只有在下面的两种情形下,才有可能:
● 从不同的模块里面访问得到的同名对象本身就是同一个对象;
● 如果从不同的模块里面访问得到的同名对象不是同一个对象,那么只要该名称并没有
被外部程序单位引用,那么也是可能的。
如下几种功能可以很容易地包装在一个模块里面:
● 全局数据,包括数据结构和公用块。
● 自定义运算。
● 软件库。
● 数据抽象。
所有模块的典型应用也就集中在这4种功能上,下面分别予以讨论。
利用模块可以很容易地在整个程序当中进行全局性的类型定义与数据声明。
模块当中的数据并不存在隐式的存储关联,也不存在任何隐式地对这些数据的的排列顺序的约定。
模块当中的全局数据可以是任意的类型,或任意类型的组合。
【例12-12】
MODULE MODELS
COMPLEX ::A(33,98)
REAL::X(50)
REAL,ALLOCATABLE::Y(:),Z(:,:)
INTEGER LVA,RVA
END MODELS
使用这个模块的方式可以有如下几种:
USE MODELS
通过这种方式可以使用模块内的任意对象以及它们的属性。
USE MODELS,ONLY:A,Z
通过这种方式可以使用模块内的对象A和Z。
USE MODELS,K=>LVA
通过这种方式可以使用模块内的任意对象以及它们的属性,只是其中的整型LVA需要改名为K。
把一个公用块封装起来的一种方法,就是把它放置在一个模块里面。
【例12-13】
MODULE COFF
COMMON…
COMMON…
COMMON…
COMMON /BLOCK1/…
END MODULE
…
PROGRAM EQU1
USE COFF
…
END
上面的例子里面,在程序EQU1里面使用了USE语句后,就可以访问模块COFF里面的公用块里面的所有变量。
运用模块来封装公用块,显然最大程度地减少了当公用块被多个程序单位使用时,所产生的错误。
模块当中的派生类型定义可以通过USE语句而得到多个程序单位的使用。
【例12-14】
MODULE NEW_TYPE
TYPE NODE_STAT
REAL X
COMPLEX Z
END TYPE NODE_STAT
END MODULE NEW_TYPE
然后,只要任何程序单位通过USE来使用该模块的话,就可以在它的内部声明属于派生类型NODE_STAT的数据对象。
算符与赋值符号都可以进行如下形式的扩展:
● 一个界面块可以用来声明新的算符,或者对固有算符定义新的含义。
● 赋值符号=也可以定义新的含义,或者对于派生类型的固有赋值也可以进行重定义。
注意,只有对于派生类型的赋值,才能进行固有算符或固有赋值的重定义。
在进行这样的扩展时,要求界面块具有OPERATOR或ASSIGNMENT属性。
一般说来,这样的界面块都放置在一个模块里面,以便利用模块的可靠性与灵活性。
【例12-15】
INTERFACE OPERATOR(.INVERSE.)
FUNCTION INVERSE(MATRIX1)
TYPE(MATRIX),INTENT(IN)::MATRIX1
TYPE(MATRIX)::INVERSE
END FUNCTION INVERSE
END INTERFACE
在上面的例子当中,运用具有OPERATOR属性的界面来定义矩阵的逆,这就要求定义一个求逆的函数以及定义自定义运算的界面块。这就是上面定义的函数INVERSE与算符.INVERSE.,然后就可以把这个自定义算符运用于其他表达式,例如:
0.5+(.INVERSE.A)
注意其中的加法+也必须扩展为一个实型值与一个矩阵的加法。
把类型定义和运算封装到一个模块当中对于相关的程序单位尤其方便。
【例12-16】
MODULE POLAR_COORDINATES
TYPE POLAR
PRIVATE
REAL RHO,THETA
END TYPE POLAR
INTERFACE OPERATOR(*)
MODULE PROCEDURE POLAR_MULT
END INTERFACE
CONTAINS
FUNCTION POLAR_MULT(P1, P2)
TYPE (POLAR), INTENT(IN) :: P1,P2
TYPE(POLAR) POLAR_MULT
POLAR_MULT = POLAR(P1 % RHO * P2 %RHO, &
P1 %THETA + P2 % THETA)
END FUNCTION POLAR_MULT
…
END MODULE POLAR_COORDINATES
在上面的例子当中,利用函数POLAR_MULT,结构构造器POLAR计算得到一个数值,表示了在极坐标里面两个变量的乘积,这样任何访问模块POLAR_COORDINATES的程序单位,都可以同时数据类型POLAR和对固有运算*的一个扩展,即极坐标乘法。
这样的一个把运算与数据对象封装到一个模块的方法,称为数据抽象。
一个模块可以包含相应于过程的一系列界面块,从而构成一个过程库。
【例12-17】
MODULE ENG_LIBRARY
INTERFACE
FUNCTION FOURIER(X,Y)
…
END
SUBROUTINE INPUT(A,B,C,L)
OPTIONAL C
…
END SUBROUTINE INPUT
END INTERFACE
END MODULE ENG_LIBRARY
其中的子例行程序INPUT可以使用如下的方式调用:
CALL INPUT (AXX, L=LXX, B=BXX)
如果多个过程都需要访问相同的类型定义和数据声明,那么它们构成一个集合,就可以都放置在一个模块里面。
【例12-18】
MODULE BOOKKEEPER
TYPE,PRIVATE::IDDATA
INTEGER IDNUMBER
CHARACTER(25) NAME,ADDRESS(3)
REAL BALANCE
END TYPE IDDATA
REAL,PRIVATE::GROSSIN,EXPENSES,PROFIT,LOSS
INTEGER,PARAMETER::NUMCUST=1000,&
NUMBER=100KUIBU
NUMCH=10
CONTAINS
SUBROUTINE ACCTS_RECEIVABLE(CUST_ID, AMOUNT)
…
END SUBROUTINE ACCTS_RECEIVABLE
SUBROUTINE ACCTS_PAYABLE(CUST_ID, AMOUNT)
…
END SUBROUTINE ACCTS_PAYABLE
SUBROUTINE PAYROLL(EMP_ID, AMOUNT)
…
END SUBROUTINE PAYROLL
FUNCTION BOTTOM_LINE(AMOUNT)
…
END FUNCTION BOTTOM_LINE
END MODULE
一个数据块程序单位提供了一个命名公用块里面的初始数据值,还包含了相应的数据说明。在数据块程序单位里面不存在可执行语句,它的唯一功能就是提供初始数据。实际上它的这个功能完全可以由模块来实现,因此这种程序单位纯粹只是FORTRAN早期版本的残留物,已经完全过时。
数据块程序单位在其他程序单位里面是通过EXTERNAL语句来引用的,它的语法形式(R1112)为:
BLOCK DATA[block-data-name]
[specification-part]
END [BLOCK DATA[block-data-name]]
数据块程序单位的一般规则如下:
● 可以只出现一个无名的数据块程序单位。
● 如果在END语句出现数据块单位名称,那么必须和BLOCK DATA语句里面的名称一样。
● 在数据块程序单位的说明部分只能出现如下表12-5所示的语句或属性,其他语句或属性则不能出现:
● 数据块程序单位可以对多个命名公用块里面的对象进行初始化。
● 无须初始化整个公用块。
● 如果在数据块程序单位里面给出了某个公用块里面的对象的初始值,那么该公用块必须是完全说明的。
● 一个给定的命名公用块可以只出现在一个数据块程序单位里面。
【例12-19】
BLOCK DATA SEQ
COMMON / BLOCK1 / A,B,C
DATA A/1.02/,B/9.01/,C/0.04/
END BLOCK DATA SEQ
表12-5 数据块程序单位的说明部分所许可的语句或属性
|
COMMON |
POINTER |
|
DATA |
SAVE |
|
DIMENSION |
TARGET |
|
EQUIVALENCE |
USE |
|
IMPLICIT |
派生类型定义 |
|
INTRINSIC |
类型声明语句 |
|
PARAMETER |
|