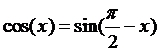 。
。如果说一个语句可以看成是一条指令,那么在FORTRAN 95语言里,一个具有一定结构的计算任务可以对应的最小程序单位,就是一个过程。
从专致于科学计算的初衷出发,FORTRAN在语言的结构层面上,可以认为是面向过程的一种语言,尽管在编程语言流行面向对象的今天,面向过程显得有点落伍,但却有效地适用于描述计算任务,当然随着现代技术对于计算的要求越来越复杂与庞大,FORTRAN也不是一味地守旧,可以预计FORTRAN的下一个版本,就会具有适应大型软件工程的要求的面向对象的语言特性。
FORTRAN 95语言作为一种语言的主要特点,可以说就体现在它的过程这个主要的程序结构上。而从我们程序编写者的角度来看,能否把一个完整的算法转写成一个完整的程序,关键也就在于能否构造出一些恰当的过程来作为程序的基本单位。
特别是对于大型的FORTRAN 95程序,需要把它分解为好几百个过程是很常见的,这时如何恰当地使用过程来构建整个程序,可以说是编写程序最主要的工作。因此如何构建过程,如何根据需求运用过程,然后在不同的过程之间建立必要的通讯,是值得我们非常仔细地加以讨论的。本章的主要任务即在于此。
由于过程具有多方面的功能与属性,因此对于过程的分类可以有多种方式。下面我们首先讨论过程的各种分类方式及其相应的分类意义,然后我们讨论有关过程引用的要点与相应概念。
过程可以有几个不同的分类方式,每种分类方式反映了过程的某个方面的特性。下面分别予以讨论。
从形式上根据调用的方式的不同,FORTRAN的过程分为两类:
● 函数;
函数返回一个可以供表达式使用的值。因此函数的调用总是作为一个表达式的算元,函数的值也就是相应表达式算元的取值。函数调用时直接使用函数的名称和它的变量,或者作为一个自定义运算,它返回值之后,它的功能就算完成,不对程序产生后效,当然,FORTRAN标准也不绝对禁止使用产生一定后效的函数。
● 子例行程序。
子例行程序的调用必须使用CALL语句,或者是作为一个赋值。
子例行程序的功能主要在于产生一定的后效,例如改写一些变元,以及全局变量,或者执行某些输入输出。
函数与子例行程序的一般规则如下:
● 函数与子例行程序在调用方式上的差别实际上来源于一个函数总是和一个相应的函数结果值相关联,只要运行或者调用一个函数,总会得到相应的函数结果值,而子例行程序却没有相应的概念,这就使得子例行程序只能依靠使用专门的CALL语句来调用,而既然函数总是能够给出一个函数值来,就可以直接把它作为表达式的算元来调用。
● 函数结果可以是任意的数据类型,例如派生类型,或者是取数组值都可以。
● 如果在FUNCTION语句当中使用RESULT属性,那么就可以给结果一个与函数定义里面的函数名称不同的名称,这主要应用于直接调用自身的递归函数。
● 在除了模块以及数据块程序单位之外的程序单位的说明部分还可以使用一种由一个语句组成的函数,称为语句函数,不过它的功能完全可以由下面的内部过程来实现,因此已经过时。
再从过程与其他程序单位的关系的角度来分类的话,过程也可以分为如下两大类:
● 外部过程;
顾名思义,外部过程就是处于任何的程序单位的外部,它作为一个孤立的过程,可以单独构造,单独编译,单独使用,而可以完全独立于任何的过程与程序单位。甚至还可以是用其他的语言编写的,例如常见的C语言。
当然,一个外部过程还是可以通过变元列表,模块,公用块等来共享数据与过程之类的信息。
● 内部过程。
内部过程总是定义在一个程序单位内部,该程序单位就称为它的宿主。
当一个过程出现在它的宿主内部的时候,总是出现在宿主的CONTAINS语句和END语句之间。
一个内部过程对于其宿主而言,总是局域的,而且通过宿主关联继承了宿主的数据环境。
特别的,如果一个内部过程的宿主是一个模块,那么这种内部过程被单独称为模块过程。
● 模块过程。
模块过程同样必须出现在其宿主模块里面的CONTAINS语句和END语句之间。
一个模块同样可以通过宿主关联继承宿主模块的数据环境。 但与一般内部过程不同的是,模块内的模块过程可以具有PUBLIC属性,即从模块外部可以直接访问具有PUBLIC属性的过程;当然模块过程也可以具有PRIVATE属性,使得模块外部不能访问该过程。
注意在早期FORTRAN版本里面出现过语句函数的概念,它是出现在程序单位的说明部分的单语句定义的函数,不能够出现在模块或数据块程序单位当中。由于它的功能可以完全由内部过程替代,因此语句函数的概念已经过时。
一般由多个过程组成过程子程序。对于内部过程来说,组成过程子程序的多个过程可以通过宿主关联而获得对宿主数据环境的共享;而对于外部过程来说,当一些外部过程要组成过程子程序的时候,由于缺乏类似的关联机制,它们的数据共享问题是通过所谓过程登录机制来解决的。
所谓过程登录是通过运用ENTRY语句来说明一个过程与一个过程子程序的关联关系的。每一个ENTRY语句就给出了一个过程,所有这些过程就可以共享该过程子程序的数据环境。例如两个不同的函数SIN和COS就可以通过这种方式使用同一个外部子程序,因为SIN和COS具有如下的关系:
。
尽管对于内部过程来说,过程登录是不必要的,但也可以应用于模块过程。
根据过程对于变元的作用效果来分类,则可以把过程分为纯过程与非纯过程。
所谓纯过程就是在执行对变元的作用之后,不会产生后效,这对于程序按照序列进行一般是没有什么影响的,但是对于程序的并行执行,却往往会给程序带来不确定性,因此就需要对一般的过程加以约束,使得其完全没有后效,从而得到纯过程。
例如过程A和B,都具有对X进行赋值的后效,设A把X赋值为1.0,而B把X赋值为2.0,那么如果A和B这两个过程是并行完成的,那么X的具体取值就变得不可预料,因此需要对过程A和B进行一定的约束,使得它们成为纯过程。
如果从过程作用于数据对象的方式来进行分类,那么过程可以分为逐元过程和变换过程。
● 逐元过程,即过程的本来属于标量形式的变元可以被赋予数组,这时过程的作用方式是对数组的每个元素进行单独的运算,得到的所有结果再构成一个与变元数组相同形状的数组,就称为该过程作用于数组后的结果。
● 变换过程,即过程的变元本来就是数组,对数组的作用方式是把数组作为一个整体进行变换,而不是逐个地针对元素进行。
因此逐元过程既可以标量变元来引用,也可以通过数组变元来引用,只是当通过数组变元来引用的时候,实际上就是通过标量数组元素来引用,只不过需要引用多次引用的次数等于数组元素的个数。
逐元过程总是纯过程,因为逐元过程不产生后效。
如果从过程的来源来看,过程还可以分为固有过程和自定义过程两类。
所谓固有过程,也称为内建过程,即FORTRAN标准已经建立好了的过程,一共包括115个固有过程。这意味着任何的FORTRAN实现,都必须能够直接提供这些固有过程。
固有过程的名称在程序单位的任何地方都是可以直接引用的,唯一的例外,就是当使用了显式的EXTERNAL语句或过程界面块的时候,固有过程的通用属性就可能被扩充,即固有过程的名称也可能用来引用非固有过程,这时该名称所表示的固有过程反而成了一种默认值。
大部分的固有过程同时还是逐元的,自定义过程也可以被定义为逐元过程,这样就极大地增强了FORTRAN的数组计算能力。
所谓过程的引用就是使得过程的名称出现在程序的恰当位置,当程序运行到该位置时,过程名称能够导致程序转入执行该过程。
过程的引用也可以称为调用或访问,在本书当中,这几个词汇是根据一般用词习惯而交替使用的。
过程的引用分为两种形式,即子例行程序的引用和函数的引用。
● 子例行程序的引用是依靠一个单独的CALL语句,某些时候也可以使用赋值语句的形式。
● 函数的引用是作为表达式的一部分,即采用函数名称及其变元列表作为表达式的项出现,某些时候,函数引用也可以采取一元运算或二元运算的形式,其变元作为表达式的算元。
过程的引用本质上就是通过变元来进行数据的传递或通讯,在进行过程的引用过程当中,变元根据它所行使的功能,还可以分为三种:实元,哑元,替代返回变元。
● 实元
在过程的引用当中,所谓实元就是在程序执行的时候需要实际采用的数据对象。例如实元在作为变量的时候,可以在每次引用当中取不同的值,因为作为实元,是直接面向具体取值的。实元的取值可以是输入值,也可以是过程运行之后返回的值,或者两者都是。
● 哑元
所谓哑元就是一个名称,通过该名称过程内部就能够访问到相应实元。因此哑元在过程被定义的时候就已经给出,在过程进行计算时,它就充当变元名称。一旦在程序运行时引用该过程,那么引用的实元就通过变元关联而与相应哑元建立关联关系。如果过程界面是显式的,那么在引用过程时,就可以直接使用哑元名称作为实元关键词。
过程定义里面的哑元名称还可以用来指称一个过程,这实际上就是一个过程引用。因为与该哑元具有变元关联关系的实元名称就是一个过程的名称,不过这个被关联的过程不能是内部过程,语句函数,已经具有类属性的过程。
● 替代返回变元
所谓替代返回是只在子例行程序里面出现的一种变元的功能,通过替代返回,就可以中断程序的顺序执行次序,控制程序的执行分支到其他某个位置,替代返回里面的实元就是分支目标语句的标签,这种分支方式经常用于从子例行程序里面出错退出的情形,不过在现代的FORTRAN控制结构里面,具有更合理的控制方式,因此这种分支方式已经过时。
过程通过变元进行通讯的途径就是关联,过程关联的形式有4种:变元关联,宿主关联,使用关联,以及共享存储关联。
● 变元关联
变元关联是过程之间进行数据通讯的主要方式。在13.7节会详细地加以讨论。
● 宿主关联
宿主关联是建立在一个过程与其所属的程序单位之间的数据关联关系。一个宿主程序单位可以是一个主程序,模块程序单位,外部过程,模块过程。这些宿主程序单位里面所有被允许访问的数据对象都可以通过宿主关联而被其包含的过程访问到。
对于宿主关联的详细讨论见第15章。
● 使用关联
一个过程可以通过一个USE语句和该USE语句所在的程序单位建立使用关联。通过使用管关联,过程可以和模块共享数据对象,也可以按照程序编写者的意愿,通过ONLY子句来隐藏某些数据对象。
对于使用关联的详细讨论见第12章。
● 共享存储关联
有关存储关联的详细讨论见第7章和第15章。
在组织程序时,除了在不同过程之间进行通讯之外,过程自身还可以构成递归的结构。即一个局部变量得到初始化之后,尽管它出现在递归的每一层里面,但是其初始化值只能够在该递归结构开始运行时有效地使用一次,因此实际上等价于对于变量使用了SAVE属性,使得每一层的递归都保留了它的变量值,可以说是一种数据的隐式保留属性。
一个过程无论是进行直接的递归还是进行间接的递归,都必须在过程定义里面的FUNCTION语句或SUBROUTINE语句里面加上关键词RECURSIVE,这个关键词的功能就是能够实现编译器对于过程调用的优化。
过程的引用并不涉及过程的具体功能,也就是对于过程的内部计算过程,在引用时是不需要考虑的,这样就可以把所有涉及到过程引用的信息集中在一起,包括过程及其变元的名称与属性,这就构成了所谓过程的界面。顾名思义,也就是一个过程与外部进行通讯的层面。
如果一个过程的这些信息对于一个引用它的程序单位来说,不是显式的,那么该过程就被称为具有隐式界面。这时,引用它的程序单位就只能依据过程名称以及过程引用里面的实元的属性来确定过程的有关信息,同时有关的哑元与实元的数据匹配都需要程序编写者预先规划好。
如果过程界面是显式,那么相关的数据匹配工作就可以完全由编译系统来完成检查。在很多的引用情形下,都一定要求被引用的过程具有显式界面,例如:
● 作为数组片断的实元;
● 指针变元;
● 可选变元;
● 关键词调用;
● 自定义运算;
● 自定义赋值;
● 自定义过程的逐元调用;
● 自定义类过程。
● 各种类型的过程的界面形式的显式或隐式的情况如下:
● 固有函数,内部过程,模块过程都是显式的界面,自定义过程也可以具有显式界面。所有固有函数的显式界面信息都包含在任何一个FORTRAN编译器内部,在对固有函数进行任何引用时,系统都可以根据实元的类型来检查与匹配相应的固有函数,从而得到一个正确的引用。因此对固有函数的引用可以直接使用函数的类名称以及关键词。
内部过程和模块过程在它的定义里面就要求具有显式界面,因此对这两种过程的引用同样是安全可靠的。
● 外部过程和语句函数都是隐式的界面。
不过在引用外部过程时,可以在引用程序单位里面为所引用的外部过程提供一个界面块,这样就等价于该外部过程具有了一个显式的界面。
有关界面的详细讨论见13.8节。
正是由于引用只与过程的界面有关,因此被引用的过程可以是使用其他语句编写的,例如C,C++等,不过使用非FORTRAN的过程可能移植性不太好,因为在不同的系统之间,其他的语言可能具有不同的过程通讯机制。
一个子例行程序就是一个完备的能够执行一定的计算任务的程序单位。它由以下五个部分构成:
● 初始的SUBROUTINE语句;
● 说明部分;
● 计算执行部分;
● 某些内部过程;
● END语句。
当一个子例行程序被调用时,从它的第一个可执行结构开始运行,它通过变元关联,使用关联,宿主关联以及存储关联与外部进行数据通讯。
下面分别讨论子例行程序的定义与引用。
一个子例行程序,无论是内部的,外部的,还是模块的,都具有以下语法形式(R1221):
[subroutine-prefix] SUBROUTINE subroutine-name &
[([dummy-argument-list])]
[specification-part]
[execution-part]
[internal-subprogram-part]
END [ SUBROUTINE [subroutine-name]]
其中所谓子例行程序的前缀(subroutine-prefix)是如下的几个可选项:
RECURSIVE
PURE
ELEMENTAL
不过其中表示递归属性和逐元属性的RECURSIVE与ELEMENTAL不能同时作为同一个子例行程序的前缀。
其中哑元列表(dummy-argument-list)里面的哑元既可以是哑元名称,也可以是星号(*)。星号表示替代返回变元。
当子例行程序被执行的时候,这些哑元就获得了同引用子例行程序时给出的实元的关联。
子例行程序的一般规则如下:
● 如果在END语句里面使用了子例行程序的名称,那么这个名称就必须和SUBROUTINE语句里面的名称一致。
● 一个内部子例行程序不能再包含一个内部子程序部分。
● 内部子例行程序不能包含ENTRY语句。
● 内部子例行程序与模块子例行程序的END语句必须是如下的形式:
END SUBROUTINE [subroutine-name]
即必须在END语句里面使用关键词SUBROUTINE。
● 如果子例行程序要实现递归结构,那么在SUBROUTINE语句里面必须加上前缀RECURSIVE。
● 在一个SUBROUTINE语句里面,不能重复使用某个前缀。
● 一个子例行程序不能同时是递归的和逐元的。参见13.4节与13.5节。
● 每个哑元都是其所在是子例行程序的局部变元。哑元可以在子例行程序里面获得显式说明,也可以在某些特定情况下获得隐式声明。
● 子例行程序里面的哑元都可以具有INTENT属性或OPTIONAL属性,但是哑指针和哑过程都不能具有INTENT属性。
● 在子例行程序里面不能使用PUBLIC属性和PRIVATE属性。
● 用于表示替代返回变元的星号*是一种过时的语言特征。
【例13-1】
下面是SUBROUTINE语句的几种形式的例子:
ELEMENTAL SUBROUTINE BESSELL1
SUBROUTINE IMBEDDING(X)
SUBROUTINE TASK()
SUBROUTINE PARTICAL(CURRENT,*)
SUBROUTINE COMPUT2
RECURSIVE SUBROUTINE WALLIS(X,Y)
【例13-2】
下面是一个子例行程序的例子:
SUBROUTINE WAVELET(A,B)
REAL A
INTEGER B
….
END SUBROUTINE WAVELET
当程序的某个位置需要调用一个子例行程序时,就在该位置使用CALL语句或者是一个自定义赋值语句。实际上对子例行程序的调用,就是给出子例行程序的名称和实元。下面首先讨论使用CALL语句的引用方式。
CALL语句的语法形式(R1211)为:
CALL subroutine-name [([subroutine-actual-argument-list])]
其中的子例行程序的实元的语法形式(R1212)为:
[keyword=] subroutine-actual-argument
其中的的关键词是子例行程序的界面里面的某个哑元名称,而子例行程序的实元则具有以下几种形式(R1214)之一:
包含一个变量的表达式;
过程名称;
作为替代返回的*标签。
以上子例行程序的引用实际上就是建立一个哑元与实元的关联。即或者是通过直接使用哑元名称作为关键词,给出相应的实元,或者是省略了关键词,但是实元在实元列表里面的顺序对应着相应的子例行程序界面里面的哑元列表的顺序,从而为每个子例行程序的哑元指定了相应的实元。
作为实元的表达式的一个特殊情况就是只有一个变量自身,这时该变量作为实元可以与具有任意INTENT(IN,OUT,INOUT)属性的哑元相关联,但一个表达式就只能和具有INTENT(IN)属性的哑元相关联。
CALL语句的引用的一般规则如下:
● 根据变元列表位置来进行实元与哑元的关联的变元,必须放置在实元列表的前面部分,而一旦在该列表当中出现了关键词,那么该关键词后面的变元就必须全部是关键词。
● 在实元列表与哑元列表的对应当中,一个实元和与之对应的非可选哑元相关联,而对于可选哑元,相应的实元可省略。
● 关键词就是子例行程序的显式界面里面的哑元名称,如果在引用里面使用关键词,那么实元就与具有该名称的哑元相关联。
● 如果在一个实元列表当中,与某个实元相关联的关键词被省略了,那么在这个列里面该实元前面的所有关键词都必须省略;一个没有关键词出现的实元列表里面的所有实元,都是依据列表位置来确定它们相应的哑元的。
● 如果一个实元列表使用了多个关键词,那么关键词的顺序是无关紧要的,如果一个实元列表里面全是关键词,那么它们的顺序可以是任意,不需要与哑元列表里面的顺序有对应关系。
● 作为替代返回说明符的星号后面的标签,必须是与CALL语句同一个作用域单位的分支目标语句的标签。
● 实元不能是内部过程或语句函数的名称。
● 与一个哑过程相关联的实元必须是一个种过程的名称,如果一个过程的类名称与种过程相同,那么实际引用的是种过程。
● 对于某些固有函数来说,它们的种固有函数名称不能用来作为实元。
过程引用的另外一种形式就是使用自定义赋值语句。可以通过自定义赋值形式得到引用的子例行程序必须具有一个ASSIGNMENT界面,在这个界面里面必须给出两个变元arg1和arg2,其中arg1具有INTENT(OUT)或INTENT(INOUT)属性,而arg2则具有INTENT(IN)属性。
自定义赋值引用的形式为:
arg1 = arg2
对于这种引用形式的详细讨论见13.8.5节。
【例13-3】下面是一个通过CALL语句引用子例行程序的例子。
CALL SUB1(100.01+X,*25) !引用SUBROUTINE SUB1
…
25 … !替代返回的目标语句
…
CALL SUB2(X=5.02,N=75) !引用SUBROUTINE SUB2(X,N)
…
【例13-4】下面是一个通过自定义赋值形式引用子例行程序的例子。
MODULE POLAR_COORDINATES
TYPE POLAR
REAL ::RHO THETA
END TYPE
INTERFACE ASSIGNMENT(=)
MODULE PROCEDURE ASSIGN_POLAR_TO_COMPLEX
END INTERFACE
…
SUBROUTINE ASSIGN_POLAR_TO_COMPLEX (Z, P)
COMPLEX INTENT ( OUT ) :: Z
TYPE (POLAR) INTENT (IN) :: P
Z= CMPLX (P%RHO * COS (P%THETA), &
P%RHO * SIN (P%THETA))
END SUBROUTINE ASSIGN_POLAR_TO_COMPLEX
USE POLAR_COORDINATES
COMPLEX ::CARTESIAN
…
CARTESIAN = POLAR(R,PI/6)
在上面最后语句里面,使用了一个赋值语句,实际上就等价于下面的CALL语句:
CALL ASSIGN_POLAR_TO_COMPLEX(CARTESIAN,POLAR(R,PI/6))
函数与子例行程序的最大区别就是函数可以用来作为表达式的项,而函数的定义的语法结构则与子例行程序类似。函数的变元用来引入初始值,然后经过函数的计算,得到函数结果,作为表达式相应的项的输入值。函数同样可以通过4种关联形式从函数外部获得数据。
一个函数子程序,不管它是外部子程序,内部子程序还是模块子程序,都具有如下的语法形式:
[function-prefix] simplest-function-statement [RESULT (result-name) ]
[specification-part]
[execution-part]
[internal-subprogram-part]
END [FUNCTION [function-name]]
其中的函数前缀(function-prefix)包括如下几种形式:
type-specification
RECURSIVE
PURE
ELEMENTAL
其中RECURSIVE和ELEMENTAL不能同时用于一个函数。
其中的最简单FUNCTION语句(simplest-function-statement)的语法形式为:
FUNCTION function-name ([dummy-argument-name-list])
其中的哑元在函数运行时获得引用实元的变量关联。
因此函数语句可以有几种不同的形式,下面是一些例子。
【例13-5】
FUNCTION LAGRANGE1 (X,Y)
COMPLEX FUNCTION SHORDINGER2(X,T)
FUNCTION LATTICE(X,Y) RESULT(CROSS)
RECURSIVE REAL FUNCTION SUM1(N,K)RESULT(SUM2)
函数遵循如下规则:
● 函数的类型既可以在函数语句当中予以说明,也可以使用单独的类型声明语句当中予以说明,但是不能同时采用这两种说明方式。如果这两种说明方式都没有出现,那么系统会认为是默认类型。
● 如果函数值是数组或指针,那么函数声明必须给出其函数结果名称的相应属性。 函数结果名称可以是显形数组或哑形数组。如果为显形数组,那么它的非常数界可以是表达式形式。
● 哑元的属性既可以在函数体当中显式说明,也可以隐式说明。
● 哑元总是相应函数的局部变量,因此哑元名称在函数内部必须是唯一的。
● 如果在END语句当中出现了函数名称,那么该名称必须和FUNCTION语句当中的函数名称一样。
● 一个内部函数不能再包含一个内部子程序。
● 一个内部函数不能包含ENTRY语句。
● 在一个函数语句当中,函数前缀不能重复出现。
● 一个函数不能同时具有前缀ELEMENTAL和RECURSIVE。参见13.4和13.5节。
● 内部函数和模块函数的END语句必须是如下形式:
END FUNCTION [function-name]
即在END语句当中必须包含关键词FUNCTION。
● 如果函数语句当中不出现结果子句,那么函数名称就用作结果变量的名称,则对函数名称的引用实质上就是对函数结果变量的引用。
● 如果函数语句当中出现结果子句,那么函数名称就不能用作结果变量的名称,则对函数名称的引用就是函数引用,属于递归调用。
● 如果函数语句当中出现结果子句,那么函数名称就不能出现在任何说明语句当中。
● 如果函数的结果值不是一个指针,那么在函数执行完毕之前,它的结果值就必须完全给定定义:如果结果值是数组,那么数组的所有元素都必须给出定义;如果结果值是结构,那么结构的所有成员都必须给出定义。
● 如果函数结果值是一个数组或指向数组的指针,那么在函数执行完毕之前,它的结果值的形状必须给定。
● 如果函数结果是一个指针,那么在函数执行完毕之前,指针的分配状态必须给定,即或者是给出其所关联的目标,或者是显式说明它的去关联状态。
● 函数的哑元的INTENT属性和OPTIONAL属性必须予以说明。不过对于哑指针和哑过程,则不具备INTENT属性。
● 在函数里面不能使用PUBLIC属性和PRIVATE属性。
● 当函数采取直接递归形式的时候,必须同时给出RECURSIVE关键词和RESULT选项,这是唯一的必须给出RESULT选项的情形。
RESULT子句的功能在于给出一个不同于函数名称的名称,用来赋予函数结果值。
如果不通过RESULT子句来给定单独的函数结果的名称,那么结果值总是赋予函数名称,这样做在函数是非递归的时候,不会带来什么不良后果,但是当函数为递归形式的时候,就会导致歧义,因为在递归引用时,对函数的引用必须和对函数结果值的引用加以区分。
例如一个函数的唯一变量是实型的标量,而它的结果值是一个数组,那么在对它进行递归引用时,如果不对它的结果另外规定名称,就会和对数组结果的引用混淆起来,在这种情况下,就必须使用RESULT子句对结果变量进行单独的命名。
因此当一个函数是直接或间接递归的时候,都必须使用RESULT子句。由于函数的结果值在递归过程当中一直在发生变化,因此函数的结果值为最后一个赋予结果名称的值。
下面是一个给出了RESULT子句的递归函数的例子。
【例13-6】
PROGRAM REVERSE_PHRASE
PRINT *,REVERSE(“The following inequalities hold for any lattice”)
CONTAINS
RECURSIVE FUNCTION REVERSE (PHRASE)RESULT(LATTICE)
CHARACTER(*) PHRASE
CHARACTER(LEN(PHRASE)) LATTICE
L=LEN_TRIM(PHRASE)
K=INDEX(PHRASE(1:L),“”,BACK=.TRUE.)
IF(K==0)THEN;LATTICE=PHRASE
ELSE;LATTICE=PHRASE(K+1;L)//“”// REVERSE(PHRASE(1:K-1))
END IF
END FUNCTION REVERSE
END PROGRAM REVERSE_PHRASE
在上面的例子里面,函数结果的长度是动态的,因此其函数界面是显式的。
函数的引用有两种形式:
● 直接在表达式里面使用函数的名称;
● 通过自定义运算的形式。
第一种函数的引用是非常直接的,就是把函数名称以及它的实元用作表达式的项。而一旦函数通过这种方式得到引用,那么引用该函数的表达式的计算,就意味着函数里面的实元已经得到计算,相应的变量关联已经建立,而该函数的定义里面的所有语句都已经得到执行,因此函数对于引用它的表达式来说,就是函数结果变量。
函数引用的一般语法形式(R1210)为:
function-name([function-actual-argument-list])
其中函数实元(function-actual-argument)的一般语法形式(R1212)为:
[keyword = ] function-argument
其中的函数变元(function-argument)具有一下几种形式(R1214)之一:
包含一个变量的表达式
过程名称
而其中的关键词(keyword)是函数界面里面的一个哑元名称。
函数引用里面的实元与函数界面里面的哑元的对应规则与子例行程序一样,或者是根据哑元列表里面的顺序与实元相应顺序的对应,或者是利用关键词来指定。
对于引用函数的表达式来说,一个变量也是一种表达式的形式,如果只是一个变量,那么它所关联的哑元可以具有任意的INTENT(IN,OUT,INOUT)属性,而对于其他形式的表达式,则其中的实元只能关联于具有INTENT(IN)属性的哑元。
注意表达式(X)总是一个表达式,尽管括号里面的X只是一个变量,因此X作为实元,只能关联于一个具有INTENT(IN)属性的哑元。
这种形式的函数引用与子例行程序引用的唯一差别,就是函数引用里面的变元列表里面不能包含替代返回,其他的规则完全与13.2.2节里面有关子例行程序引用的规则一样。
下面是在表达式里面直接引用函数的例子。
【例13-7】
X=Y+5*LEBESGUE1(3.5) !引用了函数LEBESGUE1(R)
PRINT*,ANALOG1(5.0,6.7) !引用了函数ANALOG1(I,U)
函数引用的第二种形式就是通过自定义运算的形式。
除了固有运算之外,我们总会需要定义不能由任何固有运算表示的运算,这时就可以使用函数来定义自定义运算以及给出运算符的界面块,具体是说明参见13.8.4节。利用自定义运算来引用函数的规则如下。
● 一元运算只能使用包含一个变元的函数来定义。而二元运算则使用包含2个变元的函数定义。
● 函数的变元不能是可选的,并且必须具有INTENT(IN)属性。
● 自定义算符只能采取在两个句点中间为字符串的形式,其中的字符串不能多于31个字符,而且不能包含下划线,也不能与逻辑型字面常量雷同。
● 如果自定义运算的算符与固有运算的算符发生雷同的现象,那么自定义运算肯定是对相应的固有运算进行了某些扩充,例如对于算符所适用的算元的取值范围进行了扩充。
下面是一个通过自定义运算来引用函数的例子。
【例13-8】
INTERFACE OPERATOR(.FOURIER.)
FUNCTION FOURIER_OPERATOR(X,Y)
… !这些界面部分给出函数FOURIER_OPERATOR以及
… !它的变元X,Y的属性,并且需要说明X和Y具有
… !INTENT(IN)属性。
END FUNCTION FOURIER_OPERATOR
END INTERFACE
…
PRINT*,X1 .FOURIER. Y1
在上面的例子里面,PRINT语句里面通过使用自定义运算.FOURIER.而引用了函数FOURIER_OPERATOR,而实元X1和Y1则分别对应着函数界面里面的哑元X和Y。
所谓语句函数语句,就是只包含一条FORTRAN语句的函数定义,它的一般语法形式(R1228)为:
function-name([dummy-argument-name-list])= scalar-expression
实际上语句函数的功能完全可以用内部函数来实现,而通过内部函数形式来表示同样的功能,可以使得程序更加具有结构性,因此语句函数已经过时。
与上面的语句函数等价的内部函数采用如下的形式:
FUNCTION function-name([dummy-argument-name-list])
function-name = scalar-expression
END FUNCTION
可以看到,上面采用内部函数的形式更加具有结构性。
语句函数的一般规则如下。
● 通过语句函数给出的函数以及哑元都必须是标量。
● 语句函数里面的表达式只能包含固有运算,并且都只能取标量值。表达式可以引用具有数组变元但是取值为标量的固有函数。例如固有函数SUM(A+B)就是这样的固有函数,因为它的变元都是数组,而函数结果值则是一个标量。
● 语句函数作为一种函数的定义形式,只能出现在一个程序单位,或内部过程或模块过程的说明部分。在表达式里面引用的语句函数都必须在相应的程序单位的说明部分已经经过定义,因此语句函数不能采取递归的形式,无论是直接的还是间接的递归形式都不行。
● 语句函数里面的表达式里面的命名常量和变量都必须在说明部分已经经过定义,或者能够通过宿主关联或使用关联而获得数据。
● 如果在表达式里面使用了某个数组的元素,那么该数组也必须预先在说明部分经过声明。
● 语句函数的表达式里面的任何数据对象或者是已经预先声明过,或者就是采用默认的隐式类型声明,而在该语句函数之后,如果存在对于这些数据对象的任何显式类型声,那么都必须与语句函数里面采取的隐式类型声明相兼容。
● 语句函数里面的哑元的作用域与该语句函数语句的作用域一样。
● 语句函数的哑元被预定为具有INTENT(IN)的属性,即表达式里面的任何函数引用都不能改变任何哑元的值。
● 语句函数本身不能作为实元。
● 语句函数的引用形式与其他形式的函数的引用一致,变元关联的规则也一致。只是语句函数的界面总是隐式的,因此它的实元就不能采取关键词形式。
● 由于语句函数的变元只能是标量,而显式界面只能适用于那些具有数组值结果,哑形哑元,指针变元以及关键词变元的过程,因此语句函数不能具有显式界面。下面是语句函数的几个不同形式的例子。
【例13-9】
CHARACTER (10) WORD_10
CHARACTER (20) WORD_20
WORD_10 (WORD_20) = WORD_20 (11 : 20)
REAL WAVE,X
WAVE(X)= COS(X)+SIN(X)
REAL LENS
COMPLE C
LENS(C)= REAL(C)**2 + AIMAG(C)**2
纯过程这个概念完全是FORTRAN 95为了适应并行化计算而进行的改进。由于并行化计算本质上要求进行并行计算的不同运算过程具有相对的独立性,也就是处于并行位置的不同计算单位的计算值,相互不会产生影响。而传统的来源于串行计算的FORTRAN的过程,在语言设计上,一般允许过程在执行时具有后效。
例如当一个函数的引用的目的不是需要使用函数的结果值,而是利用函数来进行值的传递,那么该函数的执行的后果,就是改变了在公用块里面的变元或变量的值。
具有后效的过程也具有类似作用,即改变公用块里面的数据对象的值。实际上除了这种作用于作用域外部的后效之外,输入输出本质上就是一种能够带来后效的操作。
显然后效对于并行计算会产生不可预计的后果。例如能够执行并行运算的FORALL结构或语句,它内部的语句执行顺序是不加以规定的,如果其中包含可能产生后效的过程,就会导致最终计算结果的不确定性。因此要想顺利地进行并行计算,就必须在进行并行计算的程序单位里面完全排除具有后效的过程。
而所谓纯过程正是这种完全不会导致后效的纯过程。
纯过程包括两类:
● 所有的固有函数和固有子例行程序MVBITS都是纯过程;
● 在FUNCTION语句或SUBROUTINE语句里面具有前缀PURE的自定义过程都是纯过程。
必须使用纯过程的上下文有以下4种情形:
● 在FORALL语句或结构里面引用的函数;
● 在说明语句里面引用的函数;
● 作为实元被调用到一个纯过程的过程;
● 被纯过程体引用的过程,包括被自定义运算或自定义赋值引用的过程。
如果一个过程被上面的上下文要求是纯过程,那么它的界面就必须是显式的,并且包含关键词PURE。
纯过程的一般规则如下:
● 纯函数的哑元必须具有INTENT(IN)属性。
● 纯子例行程序的哑元必须给出其INTENT属性,除非该哑元是过程,或指针,或替代返回变量。
● 纯过程的局部变量不能具有SAVE属性。也就是说纯过程里面的局部变量不能在过程定义的说明部分获得初始化,因为获得初始化意味着该变量自动具有了SAVE属性。
● 在纯过程里面的所有内部过程都必须是纯过程。
● 纯过程不能包含如下几种语句:
● STOP语句;
● PRINT语句;
● OPEN语句;
● CLOSE语句;
● BACKSPACE语句;
● ENDFILE语句;
● REWIND语句;
● INQUIRE语句;
● 说明外部文件的READ语句;
● 说明外部文件的WRITE语句。
● 纯过程里面的任意一个变量,只要它是公用的,或者是具有宿主关联,或者是具有使用关联,或者是具有INTENT(IN)属性,或者是与这样的变量具有存储关联,那么它就不能用于以下的上下文情形:
● 赋值语句的左边;
● 指针赋值语句;
● DO变量或隐式DO变量;
● READ语句来自内部文件的输入项;
● WRITE语句的内部文件;
● I/O语句的来自内部文件的IOSTAT变量或SIZE变量;
● ALLOCATE语句或DEALLOCATE语句的STAT变量或分配对象;
● NULLIFY语句里面的指针对象;
● 赋值语句的右边,而该赋值语句的左边在某个层次包含了指针成员。
下面是纯过程的一个例子。
【例13-10】
PURE FUNCTION ACROSS(X,C)
REAL ACROSS
REAL,INTENT(IN)::X
COMPLEX C INTENT(IN)::C
…
END FUNCTION ACROSS
如果说纯过程的概念是为了给程序运行的并行化排除障碍,那么逐元过程的概念则是FORTRAN 95实现程序运行的并行化的强有力工具。
逐元过程的哑元都是标量,逐元函数的结果值也是标量,而它实现并行化计算的功能就体现在任意调用它的实元可以是任意秩的数组。
一般说来任意形式的实元数组都是与逐元过程的标量哑元相匹配的,不过还是有如下两种例外情形:
● 如果一个固有函数带有变元关键词KIND,那么相应的实元就不能是数组,而只能是一个标量整型初始化表达式。
● 如果一个自定义函数的哑元用于一个说明表达式,那么与该哑元相关联的实元就只能是标量。
那么一个以标量为哑元的逐元过程是如何作用于数组实元的呢?实际上该过程的作用对象仍然是标量,即逐元过程作用于数组实元的每一个标量元素,然后对于每一个元素得到相应的值,所有这些值构成一个集合,就是该逐元过程作用于数组实元所得到的数组值。至于该过程对数组实元的元素的作用顺序,则是不加以规定的,因为正是不规定顺序,才能实现不同元素相互独立的计算处理进程的并行化,否则,如果强制性地规定对于元素的处理顺序,那就回到了串行序列处理的方式,无法发挥具有并行处理功能的系统的并行处理能力。
当然具体的针对数组元素的运行方式,是由系统决定的,如果系统不支持并行计算,那么系统会采取默认的顺序安装串行方式来运行;如果系统支持并行运算,那么就会根据系统的并行能力,做到某些元素是同时加以计算处理的。
实际上,FORTRAN 95把逐元过程的概念从固有过程扩展到自定义过程是FORTRAN语言的一个显著进步,类似于在FORTRAN90实现的把过程类属的概念从固有过程扩展到自定义过程。
对于逐元的自定义过程来说,在FUNCTION语句或SUBROUTINE语句里面必须加上前缀说明ELEMENTAL,以说明该自定义过程为逐元过程。
由于逐元过程本来就是用来进行并行计算的,因此任何逐元过程首先必须是纯过程。这样在出现了ELEMENTAL前缀之后,也可以再加上前缀PURE,但完全是多余的。
由于逐元过程同时也是纯过程,使得纯过程的所有规则(参见13.4节)也都适用于逐元过程,另外逐元过程还遵循下面列举的规则。
● 逐元过程不能是递归的。
● 逐元过程的哑元不能是指针。
● 逐元函数的结果不能是指针。
● 逐元子例行程序的哑元不能是替代返回变量。
● 逐元过程的哑元不能是一个过程。
● 逐元过程在任何引用它的程序单位里面都必须具有显式的界面。
【例13-11】
ELEMENTAL FUNCTION QUADRIC(Z,X)
REAL QUADRIC
REAL,INTENT(IN)::X
COMPLEX,INTENT(IN)::Z
…
END FUNCTION QUADRIC
…
…QUADRIC((3.0,5.4),6.8)
!此处调用具有标量变元的函数QUADRIC
…
…QUADRIC(C1,X1)
!此处的C1和X1分别为适当的复型数组和实型数组,因此此处
!调用的实元为数组变量,而该调用的结果为分别与这两个实元相
!匹配的数组。
有五个语句是专门为在程序当中运用过程服务的,它们都是通用的语句,也就是能够用于任何形式,任何种类的过程。这些语句列举如下:
● RETURN语句;
● CONTAINS语句;
● ENTRY语句;
● EXTERNAL语句;
● INTRINSIC语句。
下面分别说明它们的功能。
RETURN语句的功能就是终止过程的执行,使得程序的运行返回到引用该过程的程序单位。
由于过程的结构当中本身含有END语句,因此RETURN语句的功能在大多数情况下,都可以直接由过程自身的END语句来完成。不过RETURN语句还具有一个功能却是END语句无法替代的,即RETURN语句能够放置在一个过程内部的执行部分的任意位置,使得过程能够在执行的任意时刻中断,返回到引用该过程的程序单位。
RETURN语句的语法形式(R1226)为:
RETURN [scalar-integer-expression]
其中的选项标量整型表达式(scalar-integer-expression)只能用于子例行程序,并且是用于替代返回的情形。
其中的表达式只能是整型的,取值范围为1到n,n表示变元列表当中替代返回变元的位置,即列表从左到右的顺序位置。表达式的取值就表示所选择的从过程返回的位置。这个替代返回的作用可以用GO TO语句的形式表示,例如:
CALL SUBROUTINE22(…,SELE)
GO TO (label-list),SELE
这样在程序从子例行程序SUBROUTINE22返回之前,与SELE相应的哑元就被赋予为整型表达式替代返回值,
实际上这样的替代返回的功能完全可以通过使用CASE结构来完成,并且CASE结构能够使得程序更加结构化,因此相对而言,使用RETURN语句是一种过时的风格。
CONTAINS语句只是起一种隔离标志的作用,即把内部过程从它的宿主单位的说明部分或执行部分里面隔离标记出来,或者是把模块过程从它所在模块说明部分隔离标记出来。
CONTAINS语句的语法形式(R1227)为:
CONTAINS
即在需要予以标记的过程前面一行使用CONTAINS一个词即可。
CONTAINS语句不是可执行的,它只是起一个标记的作用,把过程从其所在的程序单位隔离开,这样当程序运行到CONTAINS语句时,它后面的语句就不会接着执行,而是直接转移到该程序单位的END语句。
ENTRY语句的功能是为过程与过程子程序之间提供数据共享。即在一个过程子程序的说明部分或执行部分给出一条ENTRY语句,就定义了相应的过程登录,该被登录的过程也就可以访问其所在子程序的数据环境。
ENTRY语句的语法形式(R1225)为:
ENTRY entry-name [([dummy-argument-list])] [RESULT(result-name)]
如果该登录出现在一个函数内部,那么它的哑元(dummy-argument)与结果(result-name)的属性都必须在子程序的说明部分预先予以说明。
ENTRY语句的功能实质上可以看作是在一个函数子程序或一个子例行程序子程序里面,引入一条FUNCTION语句,或SUBROUTINE语句的非常灵活的一种方法。当然登录进来的名称不能与子程序里面已有的任何名称以及子程序本身的名称相冲突。
为了更加清晰地说明ENTRY语句的功能,下面给出一个例子。
【例13-12】
SUBROUTINE COUNT1(dummy-argument-list1)
…
RETURN
ENTRY OP1(dummy-argument-list2)
…
ENTRY OP2(dummy-argument-list3)
…
RETURN
END SUBROUTINE COUNT1
在上面的子例行程序COUNT1里面,至少登录了两个过程OP1和OP2,ENTRY语句之间是一系列的可执行语句,它们构成了被登录过程。一旦某个登录过程被其所在子程序单位所调用,那么整个子程序单位的运行就转到该ENTRY语句,按照通常的方式执行该过程,然后忽略后续的任何ENTRY语句,一直到遇到RETURN语句,或者是到达了子程序单位的END语句。
在很多的实际情况下,一个子程序里面登录的过程都是非常类似的计算过程,可能具有相同的数据对象以及代码,那么就不需要在多个ENTRY语句体里面进行重复,完全可以只在最后一个ENTRY语句里面出现,然后运用适当的分支来访问该ENTRY体。如果不希望使用分支方式的话,也可以把这个公共的数据与代码封装为一个内部过程,随时供整个子程序单位访问。
这样一个函数子程序里面的所有ENTRY语句就定义了相应的函数子过程,而一个子例行程序子程序里面的所有ENTRY语句也定义了相应的子例行程序子过程。对于函数子程序里面的ENTRY语句来说,它的RESULT选项与FUNCTION语句里面的RESULT选项的涵义与形式都是一样的。
ENTRY语句的一般规则如下:
● 如果ENTRY语句是出现在一个函数子程序里面,那么ENTRY语句里面用来隔离可选哑元列表的括号必须出现。
● 只有外部子程序与模块子程序可以使用ENTRY语句,内部子程序不能使用ENTRY语句。
● 在外部子程序与模块子程序里面可以使用任意有限数目的ENTRY语句。
● 在可执行结构,例如IF,DO,CASE,FORALL,WHERE这些结构里面,或者是非块DO循环里面,都不能使用ENTRY语句。
● 登录名称不能与其所在子程序的任何哑元名称相冲突。
● 登录名称不能出现在子程序的EXTERNAL语句,INTRINSIC语句,以及过程界面块里面。
● ENTRY语句里面的RESULT选项只能用于函数登录,因此只能出现在函数子程序里面。
● 如果在一个函数登录里面指定了一个RESULT名称,那么该名称不能与子程序里面的其他RESULT名称,以及登录名称和函数名称相冲突;而且相应的登录函数名称不能出现在子程序的任何说明语句当中,函数名称的属性与其结果名称的属性保持一致。
● ENTRY语句当中不能使用关键词RECURSIVE。实际上在子程序里面的初始SUBROUTINE语句或FUNCTION语句里面使用或不使用RECURSIVE关键词,就表示了该子程序里面的所有ENTRY过程都具有或不具有RECURSIVE属性。
● 如果在一个函数子程序里面的所有ENTRY函数的结果,都具有相同的类型,种别参数,以及形状,那么它们可以看成是同一个结果变量。而对于该结果变量的性质没有任何限制。
● 如果一个函数子程序里面的所有ENTRY函数以及它们的函数结果,并不具有完全相同的数据属性,即不具有完全相同的类型,种别参数,以及形状,那么它们都必须是标量,并且不能具有指针属性,必须属于默认整型,或默认实型,或默认复型,或双精度实型,或者默认逻辑型。因为一个子程序里面的所有ENTRY结果与函数结果都是相互之间具有存储关联关系的。
● ENTRY语句所给出的哑元不能出现在该ENTRY语句之前的可执行语句里面,也不能出现在该ENTRY语句之前的语句函数的标量表达式里面,除非该哑元同时也是其所在语句函数的哑元。
● 如果一个可执行语句或语句函数依赖于某个登录过程的哑元,或者通过一个局部数据对象而间接依赖于某个登录过程的哑元,例如尺度依赖某个登录过程的哑元的局部动态数组,那么只有在该哑元出现在引用过程的ENTRY语句的可选哑元列表里面的情形下,该可执行语句或语句函数才能够得到执行。而在该哑元可选的情况下,其所关联的实元也必须存在。
● 在ENTRY语句里面的哑元的名称,顺序,数目,类型,种别参数都可以不同于其所在子程序的FUNCTION语句,或SUBROUTINE语句,以及任何其他ENTRY语句里面的哑元。
● 对于外部子程序来说,由ENTRY语句定义的过程的界面可以在另外的作用域单位里面,通过在过程界面块里面给出界面体,而显式地表示出来,这时ENTRY语句必须作为界面体的第一条语句,而且关键词ENTRY必须用关键词FUNCTION或SUBROUTINE替代。如果子程序是递归的话,那么界面体当中必须包括关键词RECURSIVE,并且必须给出哑元的属性;如果过程为函数的话,则还需给出函数结果的属性。对于模块过程里面的ENTRY过程来说,其界面已经在引用该模块的程序单位里面显式地给出。
下面是不同形式的ENTRY语句的例子。
【例13-13】
ENTRY SUB_WAVELET (X) !登录子例行程序
ENTRY FUN_FACTOR(A,B) RESULT(CO_FACTOR)
!登录函数,必须具有RESULT选项
EXTERNAL语句用于说明某个程序单位里面没有加以说明的名称为过程名称。其具体用法参见7.7.1节。
考虑如下的程序单位的片断:
…
X=SIN(A)* COS(B)
CALL SUB1(A,B)
CALL SUB2(X,SUB1,C)
…
单纯从上面的片断里面,就可以判断里面的X,A和B为变量名称,而SUB1,SUB2为过程名称,但是无法判断C属于变量名称还是过程名称,因此在程序单位的其他位置必须说明C的性质,如果没有说明,则系统默认该变元为变量。而如果希望指定该变元为过程,就需要使用EXTERNAL语句。
EXTERNAL语句的一般规则如下:
● 通过EXTERNAL语句给出的过程名称必须是其所在程序单位的实元,相应的过程则必须是外部过程或哑过程,而不能是内部过程,语句函数或类属过程,因为这几种过程的名称不能作为实元。
● EXTERNAL给出的名称不能作为过程名称出现在其所在的作用域单位的界面块里面。
由于在一个程序单位里面给出外部过程的界面块也能够实现EXTERNAL语句的类似功能,因此从结构化编程的角度出发,EXTERNAL语句属于过时的语言成分。不过EXTERNAL还具有关联数据块程序单位的功能,因此还不能说EXTERNAL语句完全可以废弃。
INTRINSIC语句的功能与EXTERNAL语句的功能类似,只是INTRINSIC语句用来指示固有过程,而EXTERNAL语句用来指示外部过程。INTRINSIC语句的具体用法参见7.7.2节。
考虑下面的【例13-14】
…
CALL SUB1(X,Y,LOG)
…
如果在上面的子例行程序的引用里面出现的名称LOG没有被其所在的程序单位额外指定为某个特定的过程名称,那么LOG就表示FORTRAN的固有过程,这时就需要使用INTRINSIC语句来说明这点。
由于固有过程已经被系统内在地加以定义,所以不需要具有界面块,因此界面块无法替代INTRINSIC语句的功能,这点与EXTERNAL语句是不同的。
本章后面的变量关联与过程界面这两节围绕着一个主题,即过程之间的通讯。
一个过程是一个完整的FORTRAN计算结构,而一个实际的计算任务常常需要多个不同的过程组合起来,这样就存在一个程序如何一个过程通讯的问题,即如何与过程传递数据的问题。
归根结底,如果把数据看成内容物的话,那么装载数据的容器就是变元。而数据通讯就可以归结为如何在不同的变元之间交换它们的内容物,也就是数据。
把一个过程纳入一个程序的运行顺序,在FORTRN里面称为引用,即如果一个程序单位引用了一个过程,那么该程序单位的数据流就从属于该程序单位的变元传递到属于被引用过程的变元,使得数据流在被引用过程里面得到过程对其进行的计算处理,然后该过程再把数据结果输出到程序单位里面的用来装载过程数据结果的变元,这样就完成了对过程的引用,也完成了与过程的数据通讯。
可以看到在上面的程序单位对过程的通讯之中,涉及到两种类型的变元:
● 一类是属于程序单位的变元,用于装载程序单位对过程的输入数据与输出数据;
● 一类是属于过程的变元,作为过程的处理对象,用于表示相应数据在过程执行当中的涵义。
这两种变元的定义是完全独立的,属于程序单位的变元在其所在的程序单位里面得到定义,而完全不用考虑它将需要把数据传递到什么过程里面去;同样属于过程的变元完全在过程里面得到定义,而完全不需要考虑它将接受来自什么样的程序单位的数据输入。
正是基于这种相对性,属于引用过程的程序单位的变元称为实元,而属于被引用的过程的变元称为哑元,所谓与过程的通讯,正是实元与哑元之间的数据交换,FORTRAN称之为实元与哑元的关联,更一般地则称为变元关联。
那么如何指定需要相互进行数据交换的实元与哑元呢?FORTRAN的表述方式非常自然,我们回顾一下在定义过程的时候,例如在定义子例行程序的SUBROUTINE语句,和定义函数的FUNCTION语句里面,都在过程名称后面给出了一个哑元列表,即该过程所使用的所有哑元的一个序列,而我们在引用过程时,使用了CALL语句,在引用函数时,则直接引用函数名称,这两种方式都在过程名称后面给出了实元列表,即在程序单位里面需要经过引用过程的处理的所有变元的一个序列。那么在实元与哑元之间建立一一对应的关联的自然方法,就是利用这两个列表的变元顺序,约定两个变元列表按照从左到右的顺序是一一对应,即处于两个列表的相同的位置变元,意味着它们是相互关联的。
下面以SUBROUTINE语句和对子例行程序的CALL引用语句为例,对这种序列的按照位置的对应约定进行了图示。
SUBROUTINE name(dummy-argument1,dummy-argument2,dummy-argument3,…)
| | | …
第一对实哑对应 第二对实哑对应 第三对实哑对应...
| | | …
CALL name(actual-argument1,actual -argument2,actual -argument3,…)
图13-1 实元与哑元之间的按照顺序约定的关联
因此在这种基本的实元与哑元的关联表示当中,两个变元列表的变元位置是基本的表达方式。本节我们将更加仔细地分小节说明建立这种关联关系的各种规则与变化形式。
变元关联的本质就是变元之间交换数据值,而变元本身在各自的程序单位,或过程内部肯定是经过定义的,或者是显式地定义,或者是存在默认定义,这就对变元之间的数据交换构成了前提,即一个变元通过交换数据而获得的数据的属性不能与变元本身被定义的属性相冲突,这就是变元关联时的数据属性匹配问题。
对于所谓实元,具有明确的数据内容,并且属于所在程序单位的实际执行对象,因此它的数据属性必然是明确的。
对于所谓哑元,它并不具有实际的数据内容,也不是程序单位实际执行过程中需要处理的对象,表面上实元和哑元交换了数据内容,但是哑元本身在任何时候都没有参与程序的执行,在哑元与实元建立关联后,哑元所在过程的运行,实际上仍然是实元携带其数据内容在参与程序的运行,尽管这时的实元在该过程里面扮演的正是相关哑元的角色。
但是,哑元作为其所在过程里面的变元,却是具有明确的数据属性的,这个属性是由过程本身决定的,实元要扮演哑元在过程里面的角色,就不能与哑元的数据属性有冲突,否则该过程本身是否还有意义,都会很成问题。
例如只对实型数据有意义的一个函数,如果它被引用之后,与其中哑元对应的实元可以取复型数据,那么肯定会发生该函数无法计算的后果。
因此数据属性的匹配问题,是实元与哑元双方面的问题,不能只对其中一方面进行检查。
那么变元之间的数据属性匹配要达到什么程度呢?
首先我们必须在对数据对象进行分类的基础上来讨论这个问题,因为可以作为过程变元的数据对象除了可以是固有数据类型,派生数据类型,表达式,数组,指针等常见数据对象之外,还可以是过程以及替代返回变元,对于数组,指针,替代返回,以及过程,后面都将分小节专门进行讨论,因此在本节只讨论标量。
直观地看,变元之间的数据属性匹配所需要达到的一个基本目的就是能够使得过程得到合理的运行结果,在这个前提下,所谓数据属性的匹配包含如下三个方面的要素:
● 数据类型;
● 种别参数;
● 秩。
一个数据对象的这三个方面的属性组合起来,简称为TKR模式。
变元关联的基本原则,或者说实元与哑元获得关联的基本前提,就是它们的TKR模式相同。
如果我们目前只考虑标量的话,在秩都是1的前提下,这个基本原则包含如下内容:
● 要求与一个标量实元相关联的哑元,同样必须是标量,并且必须与该实元标量具有相同的数据类型与相同的种别参数值。
● 数组的元素,结构的标量成员,字符子串都可以作为有效的标量实元。
● 由于字符型标量的变元还包括字符长度这个数据属性,而只有在保证所有字符型变元的长度都得到显式地说明前提下,才能做到有效检测匹配条件,但这样就会限制过程的使用范围,为了解决这个问题,FORTRAN给出哑长度哑元的概念,使得在不给出显式长度说明的情况下,也能够做到变元匹配,从而适当地放松了字符型变元匹配的条件:字符型哑元如果不能做到显式地说明长度,那么就必须具有哑长度属性。哑长度属性只适用于哑元,其表示方式为(*),即用星号代替长度值。该哑元的长度只有在获得实元的关联之后,才能被确定,也就是实元在把自己的值传递给哑元的同时,也把自己的长度属性值传递给了哑元。
如果不使用哑长度哑元的形式,而是给出变元长度的显式说明,那么对于非默认字符型变元,哑元与实元的长度必须是一样的;而对于默认字符型变元,则从语法上可以允许不一样,并且针对如下的不同情形进行不同的处理:
● 如果实元的长度大于哑元的长度,那么被调用过程在使用该实元值时,只取该字符型标量实元值的左端的字符子串,该子串的长度与哑元的长度一致。因此在实元的右端所有超过了哑元长度值的字符都被该过程忽略掉了。
● 如果实元的长度小于哑元的长度,则是不允许的。
为了安全与简便起见,在涉及到字符型变元的匹配时,还是把哑元设置为哑长度哑元为宜。
注意除非哑元属性是在宿主单位里面定义的,语句函数引用是满足这个基本条件的。
由于外部过程与引用它的程序单位一般都是分别进行编译的,因此系统在编译时,无法对它们进行变元匹配性质的检查,这常常导致FORTRAN程序产生匹配错误,因此FORTRAN提供了显式过程界面的机制,来解决这种匹配问题。
由于数组具有形状属性,所以和标量的匹配相比,数组的匹配还需要考虑形状的因素。
数组变元的匹配的基本原则就是实元与哑元必须具有相同的形状,这意味着实元与哑元必须具有相同的维数,每个相应的维度都必须具有相同的元素数目,它们的尺度必须相同。
当然上述原则的前提是数组哑元与数组实元都经过了显式的形状说明,才能完成匹配检查,这个前提实际上限制了过程应用的灵活性,因此与字符型变元类似,对于数组FORTRAN也提供了哑形数组的概念,使得具有哑形数组属性的哑元的过程,能够更加具有通用性。
一旦对哑元赋予哑形数组的属性,就简化了匹配条件,即只需要实元与哑元的秩相同,就保证了实元与哑元的匹配,因为对于哑形哑元来说,它的形状只有在获得实元的关联之后,才能完全确定下来,这样在秩相同的前提下,就不再存在匹配方面的冲突。
哑形哑元与实元的匹配在通过秩相同的检查之后,就按照两个数组变元的元素与元素之间的匹配条件进行检查,即按照标量的要求来进行匹配检查。这可以说是一个完整的TKR模式匹配的检查过程。
因此尽管数组比标量在结构上要复杂,但是通过引入哑形数组的概念,就大大简化了数组变元的匹配问题,我们在实际编程当中,也应该尽量运用哑形哑元来进行变元关联。
哑形数组是FORTRAN新近引入的概念,在FORTRAN的老版本里面,数组变元的匹配问题就显得要复杂得多。一方面由于存在丰富的老版本FORTRAN源码值得我们加以利用,另一方面由于数组变元的老式的通过数组元素序列建立的关联具有特别的功能,所以下面我们分别详细说明这种数组变元关联方式,以及数组元素序列关联在存储层面的有关内容。另外由于结构与数组的相似形,最后也将说明结构对象的关联方式。
如果按照元素序列关联的观点来建立数组变元之间的关联,那么在哑元为显形数组或哑形数组的情形下,就不需要要求哑元的秩和与之相关联的实元的秩一样了。
所谓建立数组元素序列(AES)关联,就是把数组看成是一个由数组元素构成的序列,这个序列的元素是按照数组元素序进行排列的,而所谓数组元素序在第6章已经给出定义,扼要地说,就是在该序列里面,从左往右看,第一个下标变化最快,而第二个下标次之,顺次类推,最后一个下标的变化最慢。这样就把数组元素排成了一个1维的线性序列。
把哑元和实元都变换成序列之后,它们之间的所谓序列关联的机制与非默认字符型数据的字符串的关联方式(13.7.1)类似,即从两个变元的左边第一个元素开始,按照序列的顺序进行元素与元素之间的关联匹配。与字符串匹配类似的是,实元的序列长度不能小于哑元的序列长度,而可以大于哑元的长度。在这种情况下,需要采取截断方式,来保证元素的一一对应的关联,截断的规则是从最左端开始对齐,按照元素序进行序列关联,一直到哑元序列结束的地方,实元所有不能与哑元元素对应的元素都被截除。
数组元素序列关联的一般规则如下:
● 如果哑元为哑形数组,那么哑元的元素组成的序列的长度会是未定的,一直到该哑元被某个实元建立关联,那么该哑元的元素序列长度就取为实元的元素序列长度。
● 如果哑元的元素为字符,那么元素逐一地进行关联的时候,还存在一个字符串长度匹配的问题,这时出现如下两种情形:
● 对于非默认字符型元素,实元数组元素的字符长度必须和哑元数组元素的字符长度,这样实元与哑元之间的元素之间的一一对应的关联就可以按照上面的规则建立起来。
● 对于默认字符型元素,任何实元数组元素的字符长度都可以和哑元数组的字符长度不同,不过这时不需要在按照元素序的元素之间进行长度的对比,而是把数组的所有元素都按照元素序串接起来,这样整个数组构成一个大的字符串,而每个字符元素都是该字符串的一个子串,然后把实元与哑元的两个大的字符串从最左端开始对齐,按照字符对字符的方式,在字符之间建立一一对应的关联,而不是以元素为单位建立关联,因为显然按照这种方式建立起来的关联有可能把元素之间的对应关系打乱,从而出现一个元素的字符与多个元素的字符具有关联关系的情形。这时,实元与哑元之间的长度匹配规则是整个实元数组元素组成的字符串的字符数目,不能少于整个哑元数组元素组成的字符串的字符数目。而实元比哑元在右端多出来的字符全部被截断。
● 按照上面的数组元素序列关联规则,实元数组与哑元数组的秩是可以不同的,但是由于实元和哑元在进行序列关联时,总是要求实元数组元素序列大于或等于哑元数组元素序列,因此有如下两个特殊情况需要注意:
● 如果哑元是标量,即秩为0的数组,那么实元可以具有任意的非0秩,这时相当于把逐元过程应用于数组对象。
● 如果哑元是数组,那么只有在哑元为显形或哑形数组,并且实元只有在是一个单独的数组元素或元素的子串的情况下,才能建立元素序列关联。
● 构成序列关联的数组元素必须都是实元。哑形数组或指针数组的元素不能与哑元元素建立关联。
● 对于默认字符型变元,实元甚至可以是数组元素的子串,而该子串不能是来自哑形数组或指针数组的元素。
至此,我们可以看到数组变元的关联匹配,在不同的情形下可以在三个层次上进行,即:
● 数组层次;
● 数组元素层次;
● 元素字符串的字符层次。
在数组层次上建立关联,必须要求变元数组的形状一样,在形状相同的基础上,就可以进行元素与元素之间的一一对应的关联。
在数组元素层次上建立关联,则是把数组看成一个线性序列,在序列的基础上进行元素与元素之间的一一对应的关联。这时要求实元序列的元素不能少于哑元序列的元素。
在元素字符串的字符层次上建立关联,只是针对默认字符型数组元素而言,因为字符型标量的关联可以建立在字符的层次上,所以由字符型元素组成的数组可以以字符为单位构成序列,对这种序列建立关联,就同样是以字符为单位,在字符与字符之间建立一一对应的关联。这时要求实元序列的字符数目不能小于哑元序列的字符数目。
显然序列关联方式远比TKR关联方式要繁复,而且容易隐藏错误,所以最好的选择,还是赋予数组哑元以哑形以及哑长度的属性,然后以TKR关联方式建立数组变元的关联。
尽管通过序列关联能够在哑元与实元的秩不一样的情形下建立关联,而这个功能是TKR方式所不具有的,但是实际上我们可以通过调用数组片断来达到同样的效果。
在引用过程时,能够调用数组的片断是数组的一个非常强有力的功能。为了实现这个功能,运用数组元素序列关联显然是不够的,因为在大多数情况下,数组片断在数组元素序里面都不是连续的,这样要引用数组片断就会很麻烦。相反如果使用哑形哑元的概念,则可以很自然地做到调用数组片断。
数组片断调用的一般规则如下:
● 数组片断的引用可以通过以下三种方式来构造:
● 运用下标三元组的数组引用;
● 运用向量下标的数组引用;
● 非最右端部分为数组值的结构成员引用。
这样就可以很自然地应用TKR模式匹配来得到正确地引用了。
● 数组片断还可以调用为显形哑元和哑尺度哑元,这时如果过程的数组变元为隐式界面的话,为了与FORTRAN早期版本兼容,则必须认为其与哑元的关联为序列关联,因此这时数组片断的引用就必须使用数组元素序列关联的形式。
● 在使用数组片断作为实元的时候,运用向量下标构造的数组片断不能是可定义的,也就是说该变元不能在过程运行时赋予新值。同时相应的哑元不能具有INTENT(OUT)或INTENT(INOUT)属性。因为在使用向量下标时,同一个实元数组元素可能是多个数组片断的一部分,这样就使得该实元数组元素同时与多个哑元元素相关联。因此如果数组片断是可定义的话,同一个实元数组元素就可能被赋予相冲突的不同的值。
● 与上面的规则类似,通过多个变元引入同一个过程的同一个数据对象不能是有定义的。
例如假设两个数组片断X(1:10)和X(5:15)都是同一个过程的实元,那么相同的元素X(5:10)就通过两个实元被引入了该过程,这时在该过程里面,这些元素都不能获得定义。
这个限制对于任意数据对象都是成立的,再例如X是一个标量,那么X可以多次出现在实元列表当中,但这样一来X就不能作为引用的结果而得到定义。
● 如果哑元是哑形的,那么相应的实元就不能是哑尺度数组。因为哑形哑元自身不具有一个完整的数组结构方面的信息,它必须从与实元的关联当中来获得形状信息,而如果实元本身也是哑尺度的话,那么就得不到完整的形状信息。不过,一个哑尺度数组的片断则是有可能作为一个实元的,因为该片断的形状信息可以是完整的。
● 如果在一个过程里面通过变元关联来引入数据对象,那么该数据对象在本过程里面只能作为哑元被定义与被引用。例如下例里面的变元X在子例行程序里面获得赋值就是非法的。
【例13-15】
CALL SUBROUTINE1(X)
…
CONTAINS
SUBROUTINE SUBROUTINE1(A)
A = 1000
…
● 如果哑元是一个具有指针属性的数组,那么实元也必须具有指针属性。
● 对于一个类过程,或自定义运算,或自定义赋值的引用,TKR模式匹配规则必须应用到它的所有变元与算元,除非该引用为逐元引用。因此在任何情形下,一个数组元素都不能被传递给一个数组哑元。
例如,如果函数SQUIRT被作为一个类过程名称引用,那么SQUIRT(X(10))的实元为标量,而相应的哑元也必须是标量,而如果一个类过程既允许使用标量哑元,也允许使用数组哑元,那么就选择使用标量哑元的相应种过程。
● 如果一个固有过程的实元是一个数组元素,那么数组就不能被传递到该固有过程,而只有数组元素才能够传递到该固有过程。
由于结构与数组类似,因此结构变元之间也可以建立按照成员顺序排列的序列关联的关系。
如果一个结构是一个外部过程的哑元,那么该结构的派生类型必须予以说明,使得它具有与相应实元的完全相同的派生类型。要实现这个结构的匹配要求,最好的方式是把派生类型的定义放在一个模块里面,使得外部过程和引用该派生类型结构的程序单位都可以通过使用关联来访问该模块,从而获得该结构的类型定义。
此外,一个比较容易出错的实现方式是建立结构之间的序列关联,这种方式使得编译器很难查错,因此应该尽量避免使用。
具有序列关联关系的实元结构与哑元结构的派生类型不需要是完全相同的,但必须是等价的,所谓两个派生类型数据对象的等价,是指它们具有相同的类型名称,相同的序列类型,按照顺序排列的成员的名称与属性都相同,并且都不能包含私有成员。
如果通过序列关联来引用结构,那么该关联的存储模式由编译器来设置。由于结构的序列关联要求成员的名称,数目,顺序和属性都相同,因此引用程序单位和被引用程序单位都可以为相关联的结构设置兼容的存储模式,从而在过程与引用程序单位之间进行正确的通讯。
所谓指针本质上就是变元之间建立关联的一种形式。任何一个数据对象都可以或者具有POINTER属性,或者具有TARGET属性,或者这两种属性都不具有,但不能同时具有这两种属性。这样作为哑元的数据对象和作为实元的数据对象就分别具有三种情形,它们的组合则一共有九种情形,下面的表13-1列出了全部的可能性。
表13-1 指针关联的组合情形
|
实元 哑元 |
POINTER属性 |
TARGET属性 |
都不具有的情形
|
|
POINTER属性 |
A TKR |
不允许出现的情形 |
不允许出现的情形 |
|
TARGET属性
|
F,与B相同 TKR或AES |
B TKR或AES |
C TKR或AES |
|
都不具有的情形 |
G,与D相同 TKR或AES |
D TKR或AES |
E TKR或AES |
其中包含两个不允许出现的情形,即哑元具有POINTER属性,而相应的实元或者具有TARGET属性,或这两种属性都不具有。还包括两个重复的情形,因此还剩下5种情形需要讨论。
对于情形E,实元与哑元都不具有POINTER属性与TARGET属性,因此属于前面讨论的一般变元关联的情形。
对于情形B,C,D,它们的实元和哑元都至少有一个具有TARGET属性,或者是都具有TARGET属性,而没有POINTER属性,这时与情形E是非常类似的,它们都可以通过TKR模式匹配或序列关联模式来进行关联匹配,因此也就遵循相应的匹配规则。
在情形B,C,D里面至少有一个变元具有TARGET属性,这意味着可以存在指针是以它们为目标的,这里存在如下两种类型:
● 在情形B和D里面,实元都具有TARGET属性,因此在引用程序单位里面就可以存在指针以该实元为目标。
● 在情形B和C里面,哑元都具有TARGET属性,因此在过程的执行的时候,过程里面局部的指针或可访问指针,或具有指针属性的其他哑元,都可以以该哑元为目标。
一旦建立了变元关联关系,任何与具有TARGET属性的实元相关联的指针就一直保持与该数据对象相关联的POINTER属性。如果相应哑元是哑形数组或标量,则成为与该哑元相关联的指针;如果相应哑元是显形数组或哑尺度数组,则是否与指针建立关联由编译系统决定。
在引用之前与实元建立了关联的指针将保持指针关联关系,一直到过程运行完毕,并且实元与哑元的关联关系被解除为止。
对于情形B和C,在哑元目标与引用程序单位可访问指针之间建立的指针关联关系一直到被引用程序运行完毕才被解除。
如果一个引用程序调用了具有相同TKR模式的一个指针和一个目标来作为两个不同的实元,那么被引用程序单位可以在引用程序作用域范围内,建立或解除此两者的指针关联关系。
情形A表明实元与哑元都可以具有POINTER属性。当哑元为指针的时候,那么在引用程序里面过程界面必须是显式的,而相应的实元也必须是具有POINTER属性。情形A所遵循的规则如下:
● 适用于TKR模式的匹配规则。
● 建立变元关联之后,哑元必须和实元具有相同的指针关联状态,而如果实元与一个目标建立了指针关联,那么哑元也必须与同一个目标建立指针关联关系。
● 在过程执行的时候,哑元的指针关联状态可以发生变化,而任何的这种变化都导致实元的指针关联状态的相应变化。
情形F和G的实元都是指针,而哑元都不是指针。在这两种情形下,实元都必须与一个目标相关联,而正是这个目标与哑元具有变元关联关系,因此这两种情形分别与情形B和D等价。
从效果上来讲,当实元具有POINTER属性,而哑元不具有POINTER属性的时候,实际上可以看成是一个指针引用,也就是引用到一个目标数据对象。
至于表中不允许出现的情形都是非法的,因为实元与哑元的指针运算有冲突。
在情形D,过程界面在引用程序单位里面可以是,也可以不是显式的,而在情形A,B和C则过程界面必须是显式的。因此引用程序单位可以把具有目标关联的指针传递给具有隐式界面的外部过程。
在实元与哑元之间建立关联的基本方式就是变元列表的依据位置的配对。不过在某些情形下,为了更加灵活地建立变元关联,还需要有不依赖于位置的配对方式,因此FORTRAN引入了通过关键词来指定关联的方式。
所谓关键词就是在实元列表当中引用的哑元的名称,该哑元被直接地显式说明与其关联的实元。这种说明变元关联的形式为:
dummy-argument-name = actual-argument
即直接使用等号来表示哑元名称与实元的关联。
【例13-16】
CALL SUBBATA(X,Y,Z,CORE=30,SHELL=PI**2)
CALL UNIT(A,B,MINI=0.23)
运用变元关键词建立关联的一般规则如下:
● 这种直接的表示方法可以应用于任意的实元,而且由于这种方式已经不需要依赖变元的列表位置,所以在实元列表当中使用这种方式的实元可以用任意的顺序。
● 这种方式还可以与依赖位置的配对方式混合使用,这时为了便于分辨通过位置配对的实元,约定使用关键词表示方法的实元必须集中在实元列表的右端,使用位置配对方式的实元则必须集中在实元列表的左端,因此只要在实元列表里面出现了一个关键词,那么该关键词后面的所有实元都必须使用关键词。
● 在两种方式混用时,必须注意在一次引用当中,同一个哑元不能使用不同的方式进行关联,因为要保证每个哑元至多只能与一个实元关联。
● 使用关键词方式的最大好处就是不需要记忆哑元列表的顺序,因此不容易出错。
● 如果出现在变元列表当中某个非列表最右端的可选变元被省略了的情形,则只有使用关键词方式才能恰当表示变元关联。
● 如果在过程的实元列表当中使用了关键词,那么在包含该引用的程序单位的作用域当中,过程的界面必须是显式的。由于固有过程,内部过程,和模块过程的界面都是显式的,因此在这些过程里面都可以使用关键词引用方式。而对于外部过程来说,要使用关键词方式,则需要在引用程序当中给出界面块,这时关键词可以与过程定义里面的哑元名称不一样,这是自动具有显式界面的固有过程,内部过程,和模块过程所不具有的功能,因此也是外部过程引用的一个特点。
一个具有OPTIONAL属性的哑元意味着该哑元在某个特定的过程引用当中,不需要获得实元的关联。
任何过程的任何哑元原则上都可以被赋予OPTIONAL的属性,也就是说没有哪个哑元是注定了要在一切引用当中都需要获得实元关联的。赋予一个哑元以OPTIONAL属性的方式有两种,即在过程定义当中使用OPTIONAL语句,或在面向对象的声明语句当中使用OPTIONAL属性说明。具体说明参见第7章。
在一个使用了位置方式表示变元关联的变元列表当中,如果可选变元是处于列表的最右端,那么在引用时就可以直接省略,因为其被省略并不影响其他非可选变元的位置变化。而如果该可选变元不是处于列表的最右端,那么要省略它,在引用时就必须使用关键词方式,除非该可选变元的右边的所有变元都可以被省略,因此一个具有可选变元的过程要求该过程具有显式的过程界面。下面是一个例子。
【例13-17】
CALL UNIT(0.85,X=FUN1(I))
…
SUBROUTINE UNIT(A,B,X,Y)
OPTIONAL B,X,Y
…
END SUBROUTINE UNIT
对于过程的可选变元来说,由于它在不同的引用环境里面,常常可能是被省略了,或获得了实元的关联,因此在一个特定的引用当中,需要在运行过程的时候,检查该过程引用的可选哑元是否获得实元的关联,即与该哑元相关联的实元是否实际存在,实现这个检查功能的固有函数即PRESENT。
该固有函数包含一个变元,即需要检查的过程的可选变元的名称。通过运行这个固有函数,返回一个默认逻辑值,从而可以确定被检查的可选哑元是否究竟在该过程引用当中获得了实元的关联。下面是使用该固有函数的一个例子。
【例13-18】
IF(PRESENT(A)) THEN
!运行条件就是哑元A具有关联实元
FUN1=FUN2(A)**2
ELSE
!运行条件就是哑元A不具有关联实元
FUN1=FUN2(B)**2
END IF
在这个例子里面,PRESENT被用来作为条件控制的条件表达式。
当一个可选哑元不出现的时候,有以下规则,这里的不出现的实际含义就是说该可选哑元不具有关联实元。
需要注意如下几点:
● 没有出现的哑元不能获得引用。
●没有出现的哑过程不能获得调用。
● 没有出现的哑元不能又作为一个与非可选哑元关联的实元出现,除非是被固有函数PRESENT引用。
● 没有出现的哑元可以作为一个与可选哑元关联的实元出现,这时后面的可选哑元不能出现。
● 一个不出现的指针哑元可以被调用为一个实元,但是该实元必须与一个同样是指针的哑元相关联,除非该指针哑元是被固有函数PRESENT引用。
除了哑过程,哑指针之外的任意哑元,都可以赋予INTENT属性。而且只有哑元可以赋予INTENT属性。具有一定的INTENT属性的哑元表示该哑元在过程里面的特定的使用方式,那么编译器就可以依据该属性来检查是否出现违背这种特定使用方式的情形出现。
INTENT属性用来说明3种不同的变元使用方式,它们的不同形式与具体含义如下:
● INTENT(IN)
这个属性用来表示该哑元只能用来给过程输入数据,而不能用来给引用程序返回过程的结果,并且在过程的运行过程当中,该属性不能改变,如果试图改变哑元的这个属性,将被视为出错。
● INTENT(OUT)
与INTENT(IN)的含义相反,这个属性用来表示该哑元只能用来给引用程序返回过程的结果,而不能用来给过程输入数据。具有INTENT(OUT)属性的哑元在过程里面获得定义之前,不能被引用。与具有INTENT(OUT)属性的哑元关联的实元必须是一个可定义的数据对象,即一个变量。
● INTENT(INOUT)
具有INTENT(INOUT)属性表示变元在进入过程时定义了值,并且在过程运行过程当中随时可以改变取值。这样如果要求一个变元在过程里面能够随时被过程更新取值,就必须赋予其INTENT(INOUT)的属性。与具有INTENT(INOUT)属性的哑元相关联的实元必须是一个可定义的数据对象,即一个变量。
注意取值为向量值下标的数组片断的实元,不能与具有INTENT(OUT)或INTENT(INOUT)属性的哑元相关联,因为它的取值是不可变的。赋予哑元INTENT属性并不要求过程具有显式界面,因为这个属性只是规定变元在过程内部的用法。不过如果在过程的界面里面显式地给出哑元的INTENT(OUT)或INTENT (INOUT)属性,那么就可以防止该哑元被不可定义的数据对象关联。
FORTRAN引入逐元过程这个概念的基本目的,就是要使得以标量为变元的过程能够具有并行计算的能力,也就是能够作用于数组。
这时,由于引用过程存在一个变元关联的匹配问题,即过程的标量哑元如何能够与数组实元匹配呢?解决的方式就是引入逐元过程的概念,来扩展变元匹配的要求。即凡是逐元过程,都可以以标量哑元和数组实元建立关联关系。
而以标量作为变元的逐元过程的结果必定也是标量,那么当逐元过程的变元与数组实元建立关联之后,该逐元过程的结果如何决定呢?基本的约定就是把该逐元过程分别作用于实元数组的每个标量元素,从而得到相应的结果标量,并返回给引用该过程的程序单位,然后所有这些结果标量构成一个集合,显然这个集合是一个具有与实元数组相同形状的数组,那么就可以把该数组看成是逐元过程作用于数组实元的结果。
因此逐元过程名称的由来就是对数组实元的元素的逐个的作用,至于对于实元数组的元素的作用顺序则不予规定,而这点正好在语言层次上赋予了系统进行并行计算的能力。
逐元过程可以具有2个以及2个以上的变元,因为标量可以与任意形状的数组匹配,所以一个逐元引用当中的实元列表可以是任意的数组变元与标量变元的组合。实际上很多的固有逐元函数都包含了作为标量的KIND哑元,它的作用在于规定相应实元的种别参数值。一个标量在一个逐元引用当中用作实元的效果,等价于该标量被扩充为具有相同元素的与数组变元具有相同形状的数组。
所有的逐元固有过程的详细说明参见附录B。
所谓类过程,就是同一个过程名称表示了2个或多于2个的不同过程,当然这些具有相同名称的过程属于同一个计算过程,只是它们的变元具有类型参数方面的差异。
由于引用的实质是依赖过程名称而进行的,那么在引用类过程名称的时候,如何具体选择某个种过程呢?显然只有依靠能够对它们进行区分的信息,而它们的区别只是在于变元的TKR模式里面的各种参数值,因此实元的TKR模式序列就可以提供足够的用来选择种过程的信息。
这样在引用这种类过程的时候,除了名称之外,还需要给出实元的TKR模式序列,就能够选择出唯一的与具有给定实元的TKR模式序列相匹配的哑元列表的种过程。
【例13-19】 如下的3种形式的固有函数SIN的引用就分别代表了SIN的3个种过程形式:
SIN(9.9)
SIN((0.1,6.4))
SIN(9D+10)
为了使得能够通过利用实元的TKR模式序列来唯一地选择类过程集合里面的某个种过程,在一个类过程集合里面的任何两个种过程的哑元列表必须符合一定的要求。这个要求就是这两个任意的哑元列表必须在其中的一个列表当中包含一个非可选哑元,该非可选哑元满足以下两个条件之一:
● 如果把两个哑元列表进行位置对应,那么该哑元不存在与之对应的哑元;或者存在与之对应的哑元,但两个哑元的TKR模式不同。
● 该哑元的名称与另外的哑元列表里面的所有哑元名称都不相同;或者存在相同名称的哑元,但它们的TKR模式不同。
前一个条件是针对按照位置匹配变元的方式而言,后一个条件则是针对关键词匹配变元的的方式而言。
一个逐元过程也可能具有一个类过程名称,而共享该类过程名称的其他某个种过程可能不是逐元的,那么在引用这样一个逐元过程的时候,就可能与对那个非逐元种过程的引用无法区分开,这时的约定是引用那个非逐元种过程,而如果该类过程集合里面不存在这样的非逐元过程,那么就引用该逐元种过程。
【例13-20】
INTERFACE SUB1
ELEMENTAL SUBROUTINE SUB2(X)
REAL X
END SUBROUTINE
SUBROUTINE SUB3(Z)
REAL Z(:)
END SUBROUTINE
END INTERFACE
REAL A(99), B(25,50)
CALL SUB1(A) !引用了SUB2
CALL SUB1(B) !引用了SUB3
由于在引用类过程时,涉及到实元列表与哑元列表的匹配,所以在引用所处的作用域单位里面,类过程集合里面的过程的界面都必须是显式的,有关过程界面的描述参见下面的13.8节。
过程的变元除了是数据对象之外,还可以是两种非数据对象之一,即替代返回变元与哑过程。下面分别说明它们的关联表达形式。
所谓替代返回是子例行程序当中的一种非正常的返回(或者说退出),它只能在子例行程序里面使用,由于它的功能完全可以通过RETURN语句的方式获得,因此它属于过时的语言成分,不提倡使用它,但还是需要了解,以便于阅读过去的FORTRAN代码。
在一个子例行程序的变元列表当中可以使用多个替代返回,而且它们在列表当中的位置也可以是任意的。在哑元列表当中,直接使用星号表示替代返回变元,作为替代返回的哑元不能是可选的,而相关联的实元也不能具有关键词。
与替代返回哑元相关联的实元必须使用一个星号后接一个语句标签来表示,该语句标签即在引用程序单位所属的作用域单位里面的返回分支目标语句的标签。
【例13-21】 下面例子给出了一个包含替代返回的子例行程序以及对它的引用。
SUBROUTINE SUB1(X,Y,*,Z,*)
….
END SUBROUTINE SUB1
CALLSUB1(A,B,*99,C,*999)
…
99 …
…
999 …
…
运用RETURN语句完全可以获得同样的功能,这里RETURN语句的形式为:
RETURN scalar-integer-expression
其中的整型标量表达式(scalar-integer-expression)的取值为从1到哑元列表当中的星号的个数n,表示子例行程序运行到该RETURN语句时,应该返回到该数字k所指示的实元列表当中第k个星号后接标签所表示的语句。继续使用上面的例子,就是:
RETURN 1 !返回到引用程序的标签为99的语句
RETURN (2) !返回到引用程序的标签为99*的语句
RETURN !从该引用里面正常返回
所谓哑过程就是一个过程名称,它可以出现在界面块里面,可以出现在EXTERNAL语句里面,或者作为一个过程的名称被引用在一个函数或子例行程序引用里面。与作为哑元的哑过程相关联的实元必须是一个外部过程,或模块过程,或固有过程,或哑过程的名称。
哑过程的一般规则如下:
● 实元不能是内部过程或语句函数的名称。
● 实元不能是类过程的名称,除非该类过程名称同时也是一个种过程的名称。
● 如果哑过程的界面是显式的,那么其相关联的实元过程必须与该界面相匹配。
● 如果哑过程被明确引用为一个函数,那么相应的实元过程也必须是一个函数。
● 如果哑过程被明确引用为一个子例行程序,或具有一个显式的子例行程序的界面,那么相应的实元过程也必须是一个子例行程序。
● 哑过程可以是可选的,但不能具有INTENT属性。
● 哑过程可以出现在函数子程序或子例行程序子程序里面。
● 实元过程可以使用关键词说明。
所谓一个过程的界面,顾名思义就是过程与过程外部进行数据交流所必须提供的信息集合。它包括过程及其哑元的名称,过程的属性,哑元列表的顺序及其属性。
如果上面所列举的信息对于引用该过程的程序单位来说是已知的,或者说是可访问的,那么该过程的界面就称为在引用程序的作用域单位里面为显式的,否则称为隐式的。
固有过程,内部过程,和模块过程的界面总是显式的;而外部过程和语句函数的界面为隐式的。
要使得外部过程的界面成为显式的,可以在引用程序的作用域单位的说明部分使用界面块。界面块的功能包括:
● 给出过程的类属性质。
● 定义新的自定义算符,并且扩展固有算符的类属性质。
● 重定义派生类型的固有赋值,或对新的数据组合形式扩展赋值运算。
● 说明一个过程为外部过程。
鉴于显式界面在FORTRAN里面的重要性,下面我们分节说明有关显式界面的各种问题。
显式界面是FROTRAN的最为重要的一个语言特性之一,因为它能够有效地根除FROTRAN编程最大的错误来源,即过程引用当中出现的数据匹配错误。
在出现以下变元数据对象与过程对象的情形下必须给出显式界面:
1. 可选变元;
2. 数组值函数;
3. 长度动态决定的字符值函数;
4. 指针值函数;
5. 用于数组片断调用的哑形哑元;
6. 具有POINTER属性与TARGET属性的哑元;
7. 关键词实元;
8. 类过程;
9. 自定义算符,实际上是调用某些函数的替代形式;
10. 自定义赋值,实际上是调用某些子例行程序的替代形式;
11. 逐元过程;
12. 要求纯过程的上下文里面的过程引用。
下面分别说明这些不同情形之所以需要使用显式界面的原因。
● 在情形1和情形7的时候需要使用显式界面的原因,可以从下面的例子里面看到。
【例13-22】
SUBROUTINE SUB1(A,B,C,D,E);OPTIONAL A,B,C
…
END SUBROUTINE
…
CALL SUB1(F,G,H,I,J) !基本的引用
CALL SUB1(F,H,I,J) !省略了第二个变元
CALL SUB1(A=F,B=G,C=H,D=I,E=J) !与第一个引用等价
CALL SUB1(A=F, C=H,D=I,E=J) !与第二个引用等价
CALL SUB1(D=I,E=J) !省略了全部可选变元
CALL SUB1(E=J,D=I) !与上面的引用等价
CALL SUB1(C=H,B=G, D=I,E=J) !省略了一个可选变元
CALL SUB1(D=I,A=F,B=G, E=J) !省略了一个可选变元
上面例子里面的引用都是有效的引用,从上面例子的最后4个引用可以看到,当存在可选变元与关键词的时候,都必须使用显式界面,使得引用程序能够建立正确的变元关联,否则由于在哑元列表里面的任意哑元都可以被设置为可选变元,而可选变元又原则上可以被省略;关键词方式又完全不依赖于列表位置,因此要建立不会产生歧义的变元关联,就必须使用显式界面。
● 在情形2和情形3里面的数据对象都具有尺度概念,即数组的尺度和字符串的长度,这些参数值都是由过程的运行来决定的,因此在引用过程当中会发生变化,这时就需要显式界面来提供明确的信息。
● 在情形4里面,引用过程需要为指针对关联的实元数据对象建立缓存,因此也需要显式界面。
● 情形5实际上是实现了FORTRAN的一个重要功能,即能够非常灵活地引用数组的任意片断,哪怕是按照数组元素序为不连续的片断。而要做到引用任意的数组片断,就需要给引用程序提供除了一般数组引用之外的额外信息,例如数组片断的具体组成等。为了能够说明数组的任意片断,在很多时候就需要非常复杂的描述片断的组成,这都要求通过显式界面来完成这个描述任务。在原则上,任何数组都可以传递给任何形式的哑元,对于具有隐式界面的数组来说,默认情况下是传递给显形数组和哑尺度数组,而哑形哑元则需要具有显式界面的数组。对于任意形式的数组片断来说,尽管也可是传递给显形数组和哑尺度数组,但这样一来系统就需要把可能非常零散的数组片断包装成一个完整的数组,再输入过程,然后从过程返回的结果又需要拆散为原来的片断形状,这显然是一个多余而繁重的任务。所以自然的解决之道就是运用哑元哑元来引用数组片断,同时给出显式界面。
● 在情形6时,由于实元本身有可能就是一个指针,那么在引用该实元时,就会发生究竟是引用该指针还是引用该指针的目标的歧义,这时就需要知道哑元是否具有POINTER属性,而显式界面即可提供这个信息。在隐式界面的情形下,默认的选择是引用目标数据对象。
● 在情形7里面的关键词本身为哑元的名称或这些名称的别名,这些都需要通过显式界面来给出。
● 在情形8里面的类过程的名称本身意味着多个不同的种过程,因此在引用时如果使用了类过程名称,就需要给出额外的信息来决定究竟引用的是那个种过程,这同样需要通过显式界面来提供信息,即在显式界面里面给出哑元的属性模式,例如TKR模式,通过哑元的属性模式的匹配机制来选择恰当的种过程。具体的说明参见13.8.3节。
● 对于传统的二元运算的函数符号,可以使用自定义算符的形式代替,因此引用这种函数时,就可以采用引用自定义算符的形式。而这种自定义算符常常按照习惯采用一些存在既有定义的算符符号,以便于阅读,这样就发生了和类过程类似的情况,即同一个算符符号可能代表了不同的运算,这时同样地需要显式界面来给予明确的说明。有关自定义算符的具体说明参见13.8.4节。
● 情形10实际上仍然还是要解决在引用类名称时如何选择种对象的问题,只是这里涉及的是不同数据类型之间的区分与转换,即在把一个数值赋值给某个数据对象之前,可能需要对该数据值进行类型或种别的转换,使得自定义赋值能够合法进行。有关的说明参见13.8.5节。
● 在情形11里面,逐元过程的引用实际上就是一种类过程引用的形式,这时需要靠秩的信息来选择恰当匹配的种过程,因此同样需要通过显式界面来提供这个信息。
● 在情形12里面,之所以要求显式界面,是因为在有可能涉及到并行运算的情况下,例如FORALL结构或语句,或在一个说明表达式里面,都要求纯过程,因此只有通过显式界面来说明所引用的过程为纯过程,才能保证该引用是有效的。
所谓界面块是一个在语法上特别标示出来的程序单位,特别强调了其作为界面的功能,即当一个程序需要引用过程时,界面块能够提供所有有关该过程的信息,从而能够保障引用的正常工作。
由于界面块的基本功能是面向需要引用过程的程序,因此它必须放置在该程序的说明部分,或由该程序使用的模块里面。
应用界面块的场合基本上是如下4类:
1. 为外部过程和哑过程提供显式界面;
2. 为类过程提供完备的信息,即:类过程名称,共享该名称的所有种过程,其中所有外部过程的显式界面;
3. 定义新的运算符,或者是对已有的固有运算符或已知算符进行扩展,然后说明它们所对应的函数,并且为其中的所有外部函数提供显式界面;
4. 定义新的强制转换赋值,对固有的派生类型赋值进行扩展,给出相关的子例行程序,并且为其中的所有外部子例行程序提供显式界面。
因此界面块除了它的最为基本的为外部过程提供显式界面的功能之外,其他的三种功能实际上都是要解决在引用一个集合的名称的前提下,如何通过界面块所给出的信息来决定唯一的集合的某个元素的名称。后面的3种情形将分别在13.8.3,13.8.4,13.8.5节讨论,下面我们主要说明界面块的一般形式和上面的第一种情形。
界面块的的语法形式(R1201)为:
INTERFACE [generic-specification]
[interface-body]
[MODULE PROCEDURE procedure-name-list]…
END INTERFACE
其中类说明(generic-specification)的一般形式(R1207)为:
generic-name
OPERATOR
ASSIGNMENT(=)
其中界面体(interface-body)给出函数或子例行程序的界面,语法形式(R1205)为:
function-statement
[specification-part]
END [FUNCTION [function-name]]
subroutine-statement
[specification-part]
END [SUBROUTINE [subroutine-name]]
界面块的一般规则如下:
● 如果类说明选项省略,则MODULE PROCEDURE选项也必须省略,省略类说明的界面块形式只适用于外部过程和哑过程情形。
● 在情形2是在类说明里面给出类过程名称;在情形3是给出OPERATOR;在情形4是给出ASSIGNMENT。
● 在所有的情形里面,界面体都是用于外部过程和哑过程的。
● 界面体的说明部分只能包含对于哑元以及函数结果的说明,不能包含ENTRY语句,DATA语句,FORMAT语句,或语句函数语句。
● 在界面体的说明部分里面必须给出哑元以及函数结果的属性的完备说明,即所有在相应的过程定义里面给出的属性说明。不过哑元的名称可以改变,但属性绝对不能改变。
● 由于界面体是用来提供定义在外部作用域的过程的信息,而不是来自界面体自身所在宿主作用域的信息,因此界面体是一个相对独立的作用域单位,它不从其宿主通过宿主关联继承任何数据及其属性与规则,例如命名常量,隐式类型规则等。
● 但是界面体可以包含USE语句,因此可以通过使用关联访问相应的数据对象,例如派生类型定义等。
● 在MODULE PROCEDURE语句里面的过程名称是一个模块过程的名称,该模块过程或者是属于界面块的宿主模块,或者是可以通过使用关联访问到该模块过程。在与该界面块相同的作用域单位里面,或某个可访问的作用域单位里面,该名称不能同时以同样的类说明符出现在另外的界面里面。
● 界面块不能包含ENTRY语句,但是在界面体里面可以使用作为函数名称或子例行程序名称的登录名称来说明登录界面。
● 在一个作用域单位里面,一个过程只能具有一个显式界面。
● 界面块不能出现在数据块程序单位里面。
● 在界面体的END语句里面,关键词FUNCTION和SUBROUTINE都是可选的,这意味着一个外部程序的说明与END语句可以用来构成有效的界面体。
● 具有相同的类说明符的两个或多个类界面,可以在同一个作用域单位里面同时被直接地访问,或通过宿主关联,或通过使用关联被访问。这时,它们可以被看成是一个界面块。
● 如果过程定义里面出现了PURE,ELEMENTAL,RECURSIVE这样的关键词,那么相应的界面块里面必须给出同样的关键词,绝对不能省略。界面块最基本的应用就是给出外部过程与哑过程的显式界面。这时界面块的形式更加简单:
INTERFACE
[interface-body]
END INTERFACE
在上面的一般规则里面,需要特别注意如下几点:
● 界面块的宿主里面的IMPLICIT语句,类型声明语句,以及派生类型定义都不影响界面块内部。
● 在一个宿主程序单位里面,一个外部过程的界面体只能出现一次。
● 界面体不能用来说明固有过程,内部过程,以及模块过程,因为这些种类的过程本来就具有显式界面。
之所以提出类过程的概念是因为,当一个过程的变元采用多种不同的数据类型值时,变元取一种数据类型值,就对应着一种种过程,其变元有可能取多少种类的数据类型模式,就存在多少个不同的种过程,而这些种过程尽管表明上是不同的,但是过程的运算实质是相同的,并且通过变元的模式匹配,就足够区分不同的种过程,因此这些种过程可以拥有相同的作为一个过程种类的名称,即类过程名称,而对它们的引用也可以使用同一个类过程名称。
例如固有过程LOG,根据它的变元的不同数据类型,实际上它包含3个种过程:ALOG,CLOG,DLOG,它们的变元分别是默认实型,默认复型和双精度实型。要引用该过程,完全可以只使用它们的类名称LOG,在进行数据通讯时,可以通过变元之间的数据类型匹配而自动选择相应的种过程。
在引用类过程时,常常需要定义额外的类过程性质,这时就需要构造类过程的界面块,具有这种功能的界面块的形式为:
INTERFACE generic-name
[interface-body]
[MODULE PROCEDURE procedure-name-list]…
END INTERFACE
其中的类名称(generic-name)就是在该界面块的宿主单位里面引用的类过程的名称。这个界面块里面给出了所有共享该类名称的种过程,其中可能包括外部过程与模块过程。这两种类型的过程具有如下的差别:
● 对于外部过程来说,除了给出相应种过程名称之外,还给出其显式界面;而对于模块过程来说,只需要给出名称即可,因为其界面本来就是显式的。
● 在一个给定的宿主单位里面,一个外部过程只能出现在一个类过程集合里面;而由于MODULE PROCEDURE语句里面不需要给出显式界面,所有模块过程可以同时出现在一个宿主单位里面的多个类过程集合里面。
固然类过程都必须借助界面块而得到引用,而同时内部过程,固有过程以及语句函数都不能出现在界面块里面,那么当类过程名称同时也是某个内部过程,固有过程或语句函数的名称的时候,就必须把该名称看成类名称,或者还可以对过程类进行扩展。
【例13-23】
INTERFACE SQRT
MODULE PROCEDURE NORMAL_SQRT
END INTERFACE
在这个例子里面,作为类名称的SQRT被增加了一个自定义的过程NORMAL_SQRT。
实际上类过程名称是没有任何限制的,它可以取类过程自身所包含的种过程的名称,也可以取其他某个类过程的名称,或完全自定义的命名,对于类过程引用来说,正确的引用不在于它的名称本身,而是必须做到能够通过界面块确切地选择唯一的种过程。
因此只要能够保证一个过程引用总是能够明确地说明是对某个种过程的引用,那么在一个作用域单位里面可以同时存在多个类名称,例如通过USE语句来引入多个类过程名称。
从类过程名称而确定唯一的种过程的基本方法,就是在变元位置关联或关键词关联方式之下,运用TKR模式进行匹配。也只有通过这种方法,才能做到任何的过程引用都肯定是对唯一的种过程的引用。
【例13-24】 给定一个2变元的子例行程序SUB(A,B),设SUB是一个类过程名称,并且它的两个哑元A,B都不是可选哑元,那么实元X,Y对SUB的引用有如下几种形式:
CALL SUB(X,Y) !合法的引用
CALL SUB(X,B=Y) !合法的引用
CALL SUB(B=Y ,X) !不合法的引用
CALL SUB(A=X,B=Y) !合法的引用
CALL SUB(B=Y,A=X) !合法的引用
如果类过程SUB包含了一个种过程ESUB,那么上面的各种不同引用方式对不同情形下的种过程ESUB的影响是不同的:
● 第一种引用方式一定排除了对ESUB的引用,如果ESUB的两个变元分别与SUB的A和B都具有完全相同的TKR模式;
● 第四种和第五种引用方式一定排除了对ESUB(B,A)的引用,如果ESUB的第一个变元名称为B,并且该变元与SUB的变元B具有相同的TKR模式;同时ESUB的第二个变元名称为A,并且该变元与SUB的变元A具有相同的TKR模式。
● ESUB的其他情形都包含在对SUB的引用当中。
有关引用的TKR模式匹配问题的详细说明参见第15章。
通过运用界面块可以提供一种直观的引用函数的方式,其基本的原则与借助界面块来引用类过程一样,即扩展运算符的含义,使得算符能够用来表示函数,这时算符就相当于一个类过程,可以同时表示多个含义,再通过界面块所提供的信息,就可以选择出算符的唯一义项作为实际引用的对象。
之所以要采用算符的形式来引用函数,主要的意图是希望FORTRAN源码能够具有更加自然的数学形式,因为按照数学的习惯表示方式,对1个或2个算元的计算一般直接采用算符的形式,而FORTRAN的函数也大多是执行计算任务,因此对于包含1个或2个变元的函数,一般倾向于除了直接使用函数的定义名称作为引用名称,还采用一个算符作为函数的别名加以引用。当然这个算符既可以是对固有算符的扩展,也可以是自定义的算符,无论何种情形,都有可能导致同一个算符实际代表了几种函数或运算的含义,这时就需要使用界面块来获得引用的唯一性。
无论是扩展既有算符的含义,还是给出自定义算符,界面块的形式都是:
INTERFACE OPERATOR(defined-operator)
[interface-body]…
[MODULE PROCEDURE procedure-name-list]…
END INTERFACE
应用于自定义算符的规则与类过程的规则是一致的。不过需要特别注意以下几点:
● 每个界面体都是用于一个具有1个或2个变元的函数,而在MODULE PROCEDURE语句里面的过程名称都是一个具有1个或2个变元的函数的名称。
● 所有的变元都不是可选变元,并且都具有INTENT(IN)属性。
● 在INTERFACE语句里面给出的算符,表示了在界面块里面给出的函数的运算引用形式。对于1个变元的函数就是采用前缀算符的形式;对于2个变元的函数就是采用中缀算符的形式。
● 函数除了采用算符的形式加以引用之外,当然还可以采用直接引用函数名称的方式。
● 经过定义的算符具有以下2种形式之一:
intrinsic-operator
. letter [letter] … .
其中在字符串左右两端加句点的形式不能取逻辑值形式,而如果采用固有算符,那么就必须遵循该固有算符对于其所作用的算元的数目的约定,即算符的计算含义可以扩展,但是作用的算元数目不能变更。
● 一个自定义算符界面实际上可以看成是定义了一个类过程,该算符可以看成是类过程的名称。因此一个自定义算符实际上意味着代表了多个函数,如果把固有算符也理解为某种函数的话。
显然,引用一个自定义算符同样面临着如何通过界面块来确定唯一的选择的问题,解决的方案与类过程相同,也是利用TKR模式的匹配,甚至更加简单,因为算符的那种语法形式不允许使用关键词形式来表达变元关联,而只能使用变元的位置匹配形式。
通过TKR模式来自动地获得算符含义的唯一性基本约定是:针对一个算符的扩展只是扩展它的算元的类型与属性范畴,因此一个算符的具体含义完全通过它所作用的算元的类型属性模式来决定;如果要针对相同的算元对象构造与既有算符具有完全不同的计算含义的算符,就不能通过对既有算符的扩展来得到,而需要采用完全新的算符符号,这时就不存在如何与固有算符区分的问题了。
例如对于固有算符“+”,可以把它扩展为不同种别参数的整型与实型的加法,而如果要针对这个不同种别参数的整型与实型定义一个与该既有加法不同的运算,就不能采用“+”这个算符了。
下面的两个例子分别表示了这两种情形,即一种是属于对固有算符进行扩展的自定义运算,另一种是属于停工一个函数来全新地定义一种新的运算,具有自身的独特的算符。
【例13-25】在这个例子里面对固有算符“+”进行了扩展,使得+能够作用于一个整型数值和一个属于派生类型的区间值,这种算元模式显然扩展了固有算符“+”。
INTERFACE OPERATOR(+)
FUNCTION INTEGER_PLUS_INTERVAL (A, B)
USE INTERVAL_ARITHMETIC
TYPE (INTERVAL) :: INTEGER_PLUS_INTERVAL
INTEGER, INTENT (IN) :: A
TYPE (INTERVAL), INTENT (IN) :: B
END FUNCTION INTEGER_PLUS_INTERVAL
MODULE PROCEDURE RATIONAL_ADD
END INTERFACE
【例13-26】在这个例子里面通过模块过程VERTEX_VALENCE定义了一个全新的符.VALENCE.,它不属于任何固有算符的扩展。
INTERFACE OPERATOR(.VALENCE.)
MODULE PROCEDURE VERTEX_VALENCE
END INTERFACE
所谓赋值子例行程序本质上还是一种类过程,而这里的“赋值”只是一种采用了赋值语法形式的具有数据类型转换功能的子例行程序,即它的主要功能就是把数据值从一种TKR模式强制转换为另外一种TKR模式。本来这种功能是需要通过子例行程序来完成的,但纯粹为了使得FORTRAN源码具有更加自然的形式,就把这种特别的转换子例行程序表述为一种赋值的形式,即等号两边各有一个变元的形式。
同时,也可以把这种特定功能的自定义赋值过程看成是一个作用于两个变元的子例行程序,该子例行程序类似于上节说明的函数,具有一个唯一形式的算符“=”,即把“=”理解为一种运算,而形式上它的两边分别出现一个变元。
因此类似于自定义算符的扩展,自定义赋值过同样存在一个扩展的问题,这就使得自定义赋值具有了类过程的属性,而对自定义赋值的引用同样是通过界面块来给出唯一性信息的。
用来定义新的赋值运算的界面块采用如下的语法形式:
INTERFACE ASSIGNMENT(=)
[interface-body]…
[MODULE PROCEDURE procedure-name-list]…
END INTERFACE
这种界面块形式当然满足界面块的一般规则,此外还必须注意如下的一些特定规则:
● 每一个界面体都必须给出一个具有两个变元的外部子例行程序。
● 在MODULE PROCEDURE语句里面的所有过程都必须是具有两个变元的可访问的模块子例行程序。
● 界面块里面的变元都不能是可选的。
● 第一个变元必须具有INTENT(OUT)属性或INTENT(INOUT)属性,它将出现在赋值语句的等号的左边,用来表示经过转换而得到的数据值;第二个变元必须具有INTENT(IN)属性,它将出现在赋值语句的等号的右边,用来表示需要转换的数据值。
● 构造了赋值界面之后,就可以使用赋值语句的形式来表示对界面块里面给出的子例行程序的引用。该赋值的形式为:
variable=expression
其中等号左边的变量(variable)就是子例行程序引用里面的第一个实元,而等号右边的表达式(expression)则是子例行程序引用当中的第二个实元,因此这个赋值语句形式实际上表示了一个子例行程序引用,当然这种引用方式需要配合该自定义赋值的界面块。
● 既然是采用了赋值语句的形式,那么其中作为实元的变量必须满足赋值语句里面对于等号左边变元的语法要求。
● 赋值符号可以理解为一个类子例行程序集合的类名称,而自定义赋值界面块的功能正是给该类子例行程序集合添加自定义的外部子例行程序或模块子例行程序。
● 如果把“=”理解为算符,那么与自定义算符一样,自定义赋值的界面块还必须提供保证种子例行程序引用唯一性的信息,其唯一性的获得同样是依靠TKR模式的匹配规则。
● 如果在等号两边的变元具有不同的数据类型模式,那么该赋值等价一定于某个固有转换子例行程序,因此这种类型的赋值(或者说子例行程序)不能通过使用界面块的形式来给出,因为会导致无法唯一确定种子例行程序的情况。显然TKR模式匹配规则保证了这种情况不会出现,相应的编译系统依据这个规则就能够检查出可能的错误。
● 不过在涉及到派生类似数据的转换赋值时,可以根据具体计算的需要改变固有赋值的常规含义。例如对于以分数表示的有理数,常常在赋值之前需要进行化简,即约去分子分母的公共因子,这种添加了化简步骤的赋值就改变了固有赋值的含义。
【例13-27】在下面的赋值界面块的里面实际上给出了两个自定义子例行程序。
INTERFACE ASSIGNMENT(=)
SUBROUTINE ASSIGN_STRING_TO_CHARACTER (CH, ST)
USE STRING_DATA
CHARACTER (*), INTENT (OUT) :: CH
TYPE (STRING), INTENT (IN) :: ST
END SUBROUTINE ASSIGN_STRING_TO_CHARACTER
MODULE PROCEDURE REAL _TO_ COMPLE
END INTERFACE
然后基于这个界面块,就可以采用赋值形式来引用其中的自定义转换子例行程序ASSIGN_STRING_TO_CHARACTER和 ASSIGN_REAL_TO_COMPLEX,即:
CH = ST
CO = RE
这两个被引用的自定义子例行程序分别表示把字符串变元ST转换为字符变元CH,把实型变元RE转换为复型变元CO。
如果把过程分为外部过程,内部过程,固有过程,模块过程以及语句函数这五种的话,那么它们的各方面的性质并不是完全一致的。下面的表13-1为此进行了归纳。
表13-2 五种过程的不同性质
|
过程的性质 |
外部过程 |
内部过程 |
固有过程 |
模块过程 |
语句函数 |
|
哑元是可选的 |
是 |
是 |
是 |
是 |
否 |
|
可以通过关键词引用 |
是 |
是 |
是 |
是 |
否 |
|
可以递归引用 |
是 |
是 |
N/A |
是 |
否 |
|
定义里面可以包含CONTAINS语句 |
是 |
否 |
是 |
是 |
否 |
|
可以传递 |
是 |
否 |
是 |
是 |
否 |
|
可以出现在界面体 |
是 |
否 |
否 |
否 |
否 |
|
界面自动为显式的 |
否 |
是 |
是 |
是 |
否 |
|
可以逐元引用 |
是 |
是 |
是 |
是 |
否 |
|
可以用于定义运算 |
是 |
否 |
否 |
是 |
否 |
|
可以作为种过程 |
是 |
否 |
是 |
是 |
否 |
|
可以包含ENTRY语句 |
是 |
否 |
N/A |
是 |
N/A |
注:N/A表示该项内容不存在。